
Date: Wed, 1 Mar 2017 12:57:04 -0800 From: Conrad Meyer <cem@freebsd.org> To: Bruce Evans <brde@optusnet.com.au> Cc: src-committers <src-committers@freebsd.org>, svn-src-all@freebsd.org, svn-src-head@freebsd.org Subject: Re: svn commit: r313006 - in head: sys/conf sys/libkern sys/libkern/x86 sys/sys tests/sys/kern Message-ID: <CAG6CVpWwZhMAsVB%2Bp-N0fMVOzzQSRaYonEfE-4Z6gv%2BLGuRn9w@mail.gmail.com> In-Reply-To: <20170228121335.Q2733@besplex.bde.org> References: <201701310326.v0V3QW30024375@repo.freebsd.org> <20170202184819.GP2092@kib.kiev.ua> <20170203062806.A2690@besplex.bde.org> <CAG6CVpV8fqMd82hjYoyDfO3f5P-x6%2B0OJDoQHtqXqY_tfWtZsA@mail.gmail.com> <20170228121335.Q2733@besplex.bde.org>
index | next in thread | previous in thread | raw e-mail
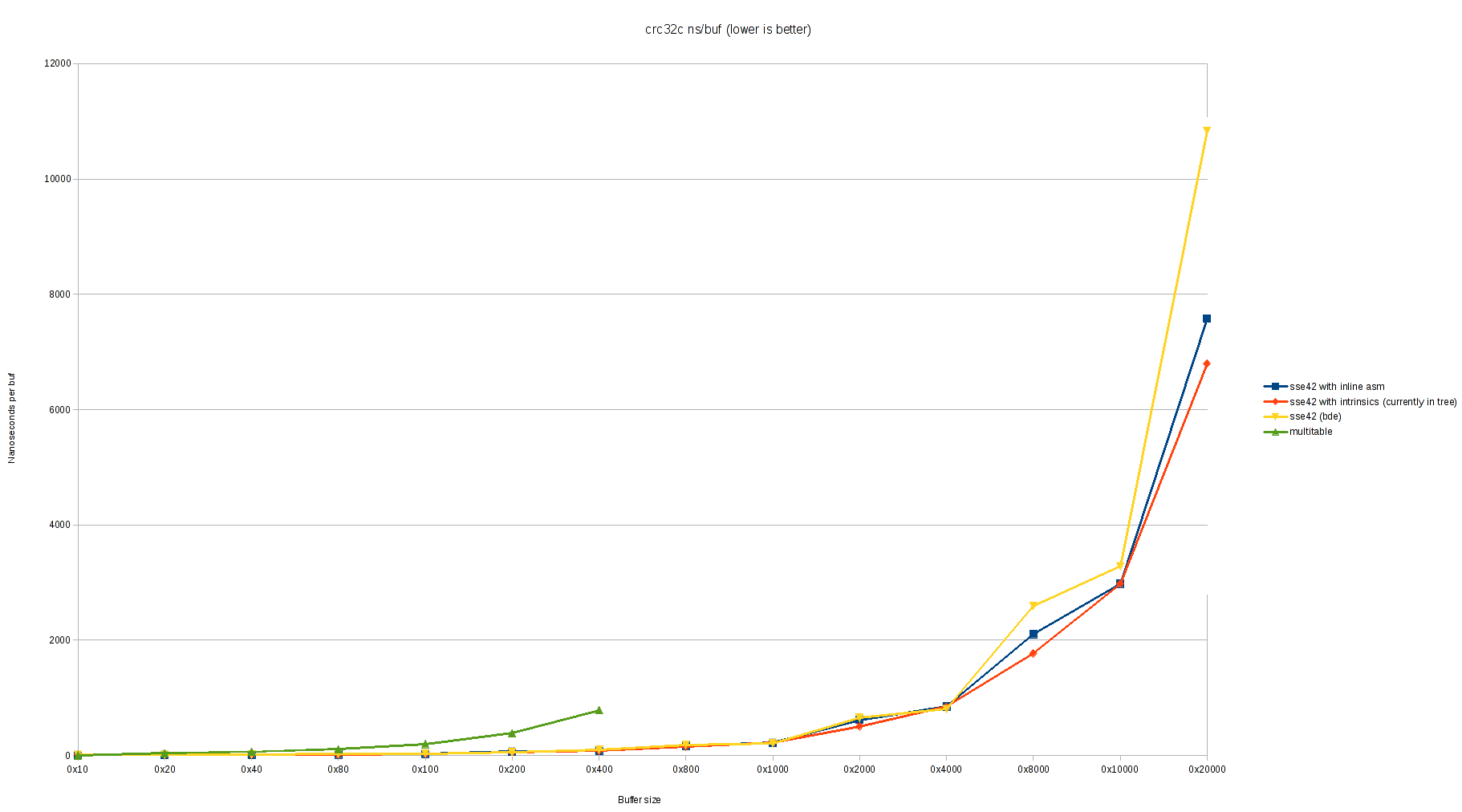
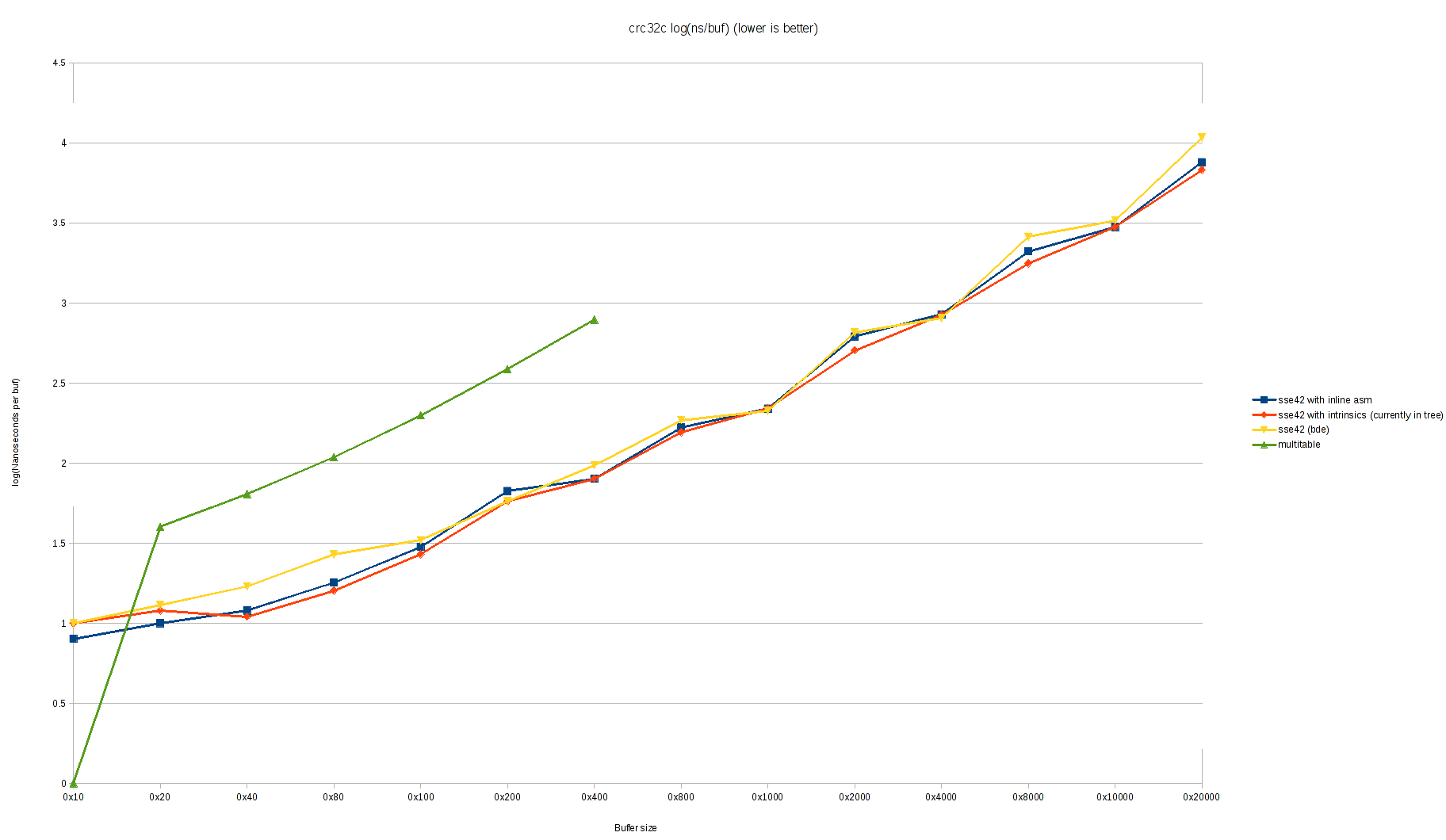
Hi Bruce, On my laptop (Intel(R) Core(TM) i5-3320M CPU — Ivy Bridge) I still see a little worse performance with this patch. Please excuse the ugly graphs, I don't have a better graphing tool set up at this time: https://people.freebsd.org/~cem/crc32/sse42_bde.png https://people.freebsd.org/~cem/crc32/sse42_bde_log.png Best, Conrad On Mon, Feb 27, 2017 at 6:27 PM, Bruce Evans <brde@optusnet.com.au> wrote: > On Mon, 27 Feb 2017, Conrad Meyer wrote: > >> On Thu, Feb 2, 2017 at 12:29 PM, Bruce Evans <brde@optusnet.com.au> wrote: >>> >>> I've almost finished fixing and optimizing this. I didn't manage to fix >>> all the compiler pessimizations, but the result is within 5% of optimal >>> for buffers larger than a few K. >> >> >> Did you ever get to a final patch that you are satisfied with? It >> would be good to get this improvement into the tree. > > > I'm happy with this version (attached and partly enclosed). You need to > test it in the kernel and commit it (I on;y did simple correctness tests > in userland). > > X Index: conf/files.amd64 > X =================================================================== > X --- conf/files.amd64 (revision 314363) > X +++ conf/files.amd64 (working copy) > X @@ -545,6 +545,9 @@ > X isa/vga_isa.c optional vga > X kern/kern_clocksource.c standard > X kern/link_elf_obj.c standard > X +libkern/x86/crc32_sse42.c standard > X +libkern/memmove.c standard > X +libkern/memset.c standard > > Also fix some nearby disorder. > > X ... > X Index: libkern/x86/crc32_sse42.c > X =================================================================== > X --- libkern/x86/crc32_sse42.c (revision 314363) > X +++ libkern/x86/crc32_sse42.c (working copy) > X @@ -31,15 +31,41 @@ > X */ > X #ifdef USERSPACE_TESTING > X #include <stdint.h> > X +#include <stdlib.h> > X #else > X #include <sys/param.h> > X +#include <sys/systm.h> > X #include <sys/kernel.h> > X -#include <sys/libkern.h> > X -#include <sys/systm.h> > X #endif > > Also fix minor #include errors. > > X X -#include <nmmintrin.h> > X +static __inline uint32_t > X +_mm_crc32_u8(uint32_t x, uint8_t y) > X +{ > X + /* > X + * clang (at least 3.9.[0-1]) pessimizes "rm" (y) and "m" (y) > X + * significantly and "r" (y) a lot by copying y to a different > X + * local variable (on the stack or in a register), so only use > X + * the latter. This costs a register and an instruction but > X + * not a uop. > X + */ > X + __asm("crc32b %1,%0" : "+r" (x) : "r" (y)); > X + return (x); > X +} > > Using intrinsics avoids the silly copying via the stack, and allows more > unrolling. Old gcc does more unrolling with just asms. Unrolling is > almost useless (some details below). > > X @@ -47,12 +73,14 @@ > X * Block sizes for three-way parallel crc computation. LONG and SHORT > must > X * both be powers of two. > X */ > X -#define LONG 8192 > X -#define SHORT 256 > X +#define LONG 128 > X +#define SHORT 64 > > These are aggressively low. > > Note that small buffers aren't handled very well. SHORT = 64 means that > a buffer of size 3 * 64 = 192 is handled entirely by the "SHORT" loop. > 192 is not very small, but any smaller than that and overheads for > adjustment at the end of the loop are too large for the "SHORT" loop > to be worth doing. Almost any value of LONG larger than 128 works OK > now, but if LONG is large then it gives too much work for the "SHORT" > loop, since normal buffer sizes are not a multiple of 3. E.g., with > the old LONG and SHORT, a buffer of size 128 was decomposed as 5 * 24K > (done almost optimally by the "LONG" loop) + 10 * 768 (done a bit less > optimally by the "SHORT" loop) + 10 * 768 + 64 * 8 (done pessimally). > > I didn't get around to ifdefing this for i386. On i386, the loops take > twice as many crc32 instructions for a given byte count, so the timing > is satisfed by a byte count half as large, so SHORT and LONG can be > reduced by a factor of 2 to give faster handling for small buffers without > affecting the speed for large buffers significantly. > > X X /* Tables for hardware crc that shift a crc by LONG and SHORT zeros. */ > X static uint32_t crc32c_long[4][256]; > X +static uint32_t crc32c_2long[4][256]; > X static uint32_t crc32c_short[4][256]; > X +static uint32_t crc32c_2short[4][256]; > > I didn't get around to updating the comment. 2long shifts by 2*LONG zeros, > etc. > > Shifts by 3N are done by adding shifts by 1N and 2N in parallel. I couldn't > get the direct 3N shift to run any faster. > > X @@ -190,7 +220,11 @@ > X const size_t align = 4; > X #endif > X const unsigned char *next, *end; > X - uint64_t crc0, crc1, crc2; /* need to be 64 bits for crc32q */ > X +#ifdef __amd64__ > X + uint64_t crc0, crc1, crc2; > X +#else > X + uint32_t crc0, crc1, crc2; > X +#endif > X X next = buf; > X crc0 = crc; > > 64 bits of course isn't needed for i386. It isn't needed for amd64 either. > I think the crc32 instruction zeros the top 32 bits so they can be ignored. > However, when I modified the asm to return 32 bits to tell the compiler > about > this (which the intrinsic wouldn't be able to do) and used 32 bits here, > this was just slightly slower. > > For some intermediate crc calculations, only 32 bits are used, and the > compiler can see this. clang on amd64 optimizes this better than gcc, > starting with all the intermediate crc variables declared as 64 bits. > gcc generates worst code when some of the intermediates are declared as > 32 bits. So keep using 64 bits on amd64 here. > > X @@ -202,6 +236,7 @@ > X len--; > X } > X X +#if LONG > SHORT > X /* > X * Compute the crc on sets of LONG*3 bytes, executing three > independent > X * crc instructions, each on LONG bytes -- this is optimized for the > > LONG = SHORT = 64 works OK on Haswell, but I suspect that slower CPUs > benefit from larger values and I want to keep SHORT as small as possible > for the fastest CPUs. > > X @@ -209,6 +244,7 @@ > X * have a throughput of one crc per cycle, but a latency of three > X * cycles. > X */ > X + crc = 0; > X while (len >= LONG * 3) { > X crc1 = 0; > X crc2 = 0; > X @@ -229,16 +265,64 @@ > X #endif > X next += align; > X } while (next < end); > X - crc0 = crc32c_shift(crc32c_long, crc0) ^ crc1; > X - crc0 = crc32c_shift(crc32c_long, crc0) ^ crc2; > X + /*- > X + * Update the crc. Try to do it in parallel with the inner > X + * loop. 'crc' is used to accumulate crc0 and crc1 > X + * produced by the inner loop so that the next iteration > X + * of the loop doesn't depend on anything except crc2. > X + * > X + * The full expression for the update is: > X + * crc = S*S*S*crc + S*S*crc0 + S*crc1 > X + * where the terms are polynomials modulo the CRC > polynomial. > X + * We regroup this subtly as: > X + * crc = S*S * (S*crc + crc0) + S*crc1. > > X + * This has an extra dependency which reduces possible > X + * parallelism for the expression, but it turns out to be > X + * best to intentionally delay evaluation of this expression > X + * so that it competes less with the inner loop. > X + * > X + * We also intentionally reduce parallelism by feedng back > X + * crc2 to the inner loop as crc0 instead of accumulating > X + * it in crc. This synchronizes the loop with crc update. > X + * CPU and/or compiler schedulers produced bad order without > X + * this. > X + * > X + * Shifts take about 12 cycles each, so 3 here with 2 > X + * parallelizable take about 24 cycles and the crc update > X + * takes slightly longer. 8 dependent crc32 instructions > X + * can run in 24 cycles, so the 3-way blocking is worse > X + * than useless for sizes less than 8 * <word size> = 64 > X + * on amd64. In practice, SHORT = 32 confirms these > X + * timing calculations by giving a small improvement > X + * starting at size 96. Then the inner loop takes about > X + * 12 cycles and the crc update about 24, but these are > X + * partly in parallel so the total time is less than the > X + * 36 cycles that 12 dependent crc32 instructions would > X + * take. > X + * > X + * To have a chance of completely hiding the overhead for > X + * the crc update, the inner loop must take considerably > X + * longer than 24 cycles. LONG = 64 makes the inner loop > X + * take about 24 cycles, so is not quite large enough. > X + * LONG = 128 works OK. Unhideable overheads are about > X + * 12 cycles per inner loop. All assuming timing like > X + * Haswell. > X + */ > X + crc = crc32c_shift(crc32c_long, crc) ^ crc0; > X + crc1 = crc32c_shift(crc32c_long, crc1); > X + crc = crc32c_shift(crc32c_2long, crc) ^ crc1; > X + crc0 = crc2; > X next += LONG * 2; > X len -= LONG * 3; > X } > X + crc0 ^= crc; > X +#endif /* LONG > SHORT */ > X X /* > X * Do the same thing, but now on SHORT*3 blocks for the remaining > data > X * less than a LONG*3 block > X */ > X + crc = 0; > X while (len >= SHORT * 3) { > X crc1 = 0; > X crc2 = 0; > > See the comment. > > X @@ -259,11 +343,14 @@ > X #endif > X next += align; > > When SHORT is about what it is (64), on amd64 the "SHORT" loop has 24 crc32 > instructions and compilers sometimes to unroll them all. This makes little > difference. > > X } while (next < end); > X - crc0 = crc32c_shift(crc32c_short, crc0) ^ crc1; > X - crc0 = crc32c_shift(crc32c_short, crc0) ^ crc2; > X + crc = crc32c_shift(crc32c_short, crc) ^ crc0; > X + crc1 = crc32c_shift(crc32c_short, crc1); > X + crc = crc32c_shift(crc32c_2short, crc) ^ crc1; > X + crc0 = crc2; > X next += SHORT * 2; > X len -= SHORT * 3; > X } > X + crc0 ^= crc; > > The change is perhaps easier to understand without looking at the comment. > We accumulate changes in crc instead of into crc0, so that the next > iteration > can start without waiting for accumulation. This requires more shifting > steps, and we try to arrange these optimally. > > X X /* Compute the crc on the remaining bytes at native word size. */ > X end = next + (len - (len & (align - 1))); > > The adjustments for alignment are slow if they are not null, and wasteful > if they are null, but have relatively little cost for the non-small buffers > that are handled well, so I didn't remove them. > > Brucehome | help
{kind=link}
{kind=link}
Want to link to this message? Use this
URL: <https://mail-archive.FreeBSD.org/cgi/mid.cgi?CAG6CVpWwZhMAsVB%2Bp-N0fMVOzzQSRaYonEfE-4Z6gv%2BLGuRn9w>