Date: Wed, 3 Oct 2012 09:21:06 -0400 (EDT) From: Rick Macklem <rmacklem@uoguelph.ca> To: Garrett Wollman <wollman@bimajority.org> Cc: freebsd-fs@freebsd.org, rmacklem@freebsd.org, hackers@freebsd.org Subject: Re: NFS server bottlenecks Message-ID: <1571646304.1630985.1349270466529.JavaMail.root@erie.cs.uoguelph.ca> In-Reply-To: <20587.47363.504969.926603@hergotha.csail.mit.edu>
next in thread | previous in thread | raw e-mail | index | archive | help
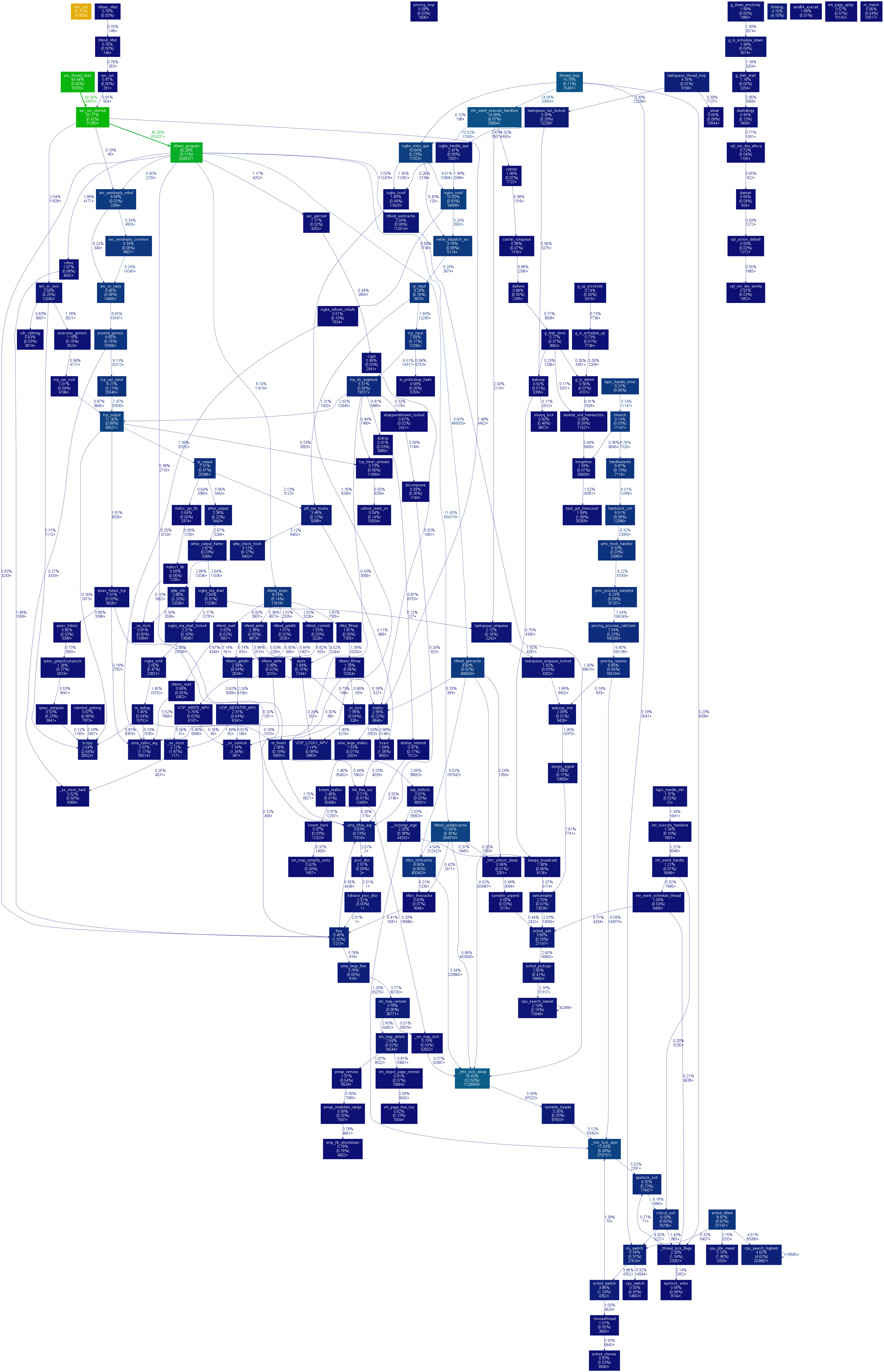
Garrett Wollman wrote: > [Adding freebsd-fs@ to the Cc list, which I neglected the first time > around...] > > <<On Tue, 2 Oct 2012 08:28:29 -0400 (EDT), Rick Macklem > <rmacklem@uoguelph.ca> said: > > > I can't remember (I am early retired now;-) if I mentioned this > > patch before: > > http://people.freebsd.org/~rmacklem/drc.patch > > It adds tunables vfs.nfsd.tcphighwater and vfs.nfsd.udphighwater > > that can > > be twiddled so that the drc is trimmed less frequently. By making > > these > > values larger, the trim will only happen once/sec until the high > > water > > mark is reached, instead of on every RPC. The tradeoff is that the > > DRC will > > become larger, but given memory sizes these days, that may be fine > > for you. > > It will be a while before I have another server that isn't in > production (it's on my deployment plan, but getting the production > servers going is taking first priority). > > The approaches that I was going to look at: > > Simplest: only do the cache trim once every N requests (for some > reasonable value of N, e.g., 1000). Maybe keep track of the number of > entries in each hash bucket and ignore those buckets that only have > one entry even if is stale. > Well, the patch I have does it when it gets "too big". This made sense to me, since the cache is trimmed to keep it from getting too large. It also does the trim at least once/sec, so that really stale entries are removed. > Simple: just use a sepatate mutex for each list that a cache entry > is on, rather than a global lock for everything. This would reduce > the mutex contention, but I'm not sure how significantly since I > don't have the means to measure it yet. > Well, since the cache trimming is removing entries from the lists, I don't see how that can be done with a global lock for list updates? A mutex in each element could be used for changes (not insertion/removal) to an individual element. However, the current code manipulates the lists and makes minimal changes to the individual elements, so I'm not sure if a mutex in each element would be useful or not, but it wouldn't help for the trimming case, imho. I modified the patch slightly, so it doesn't bother to acquire the mutex when it is checking if it should trim now. I think this results in a slight risk that the test will use an "out of date" cached copy of one of the global vars, but since the code isn't modifying them, I don't think it matters. This modified patch is attached and is also here: http://people.freebsd.org/~rmacklem/drc2.patch > Moderately complicated: figure out if a different synchronization type > can safely be used (e.g., rmlock instead of mutex) and do so. > > More complicated: move all cache trimming to a separate thread and > just have the rest of the code wake it up when the cache is getting > too big (or just once a second since that's easy to implement). Maybe > just move all cache processing to a separate thread. > Only doing it once/sec would result in a very large cache when bursts of traffic arrives. The above patch does it when it is "too big" or at least once/sec. I'm not sure I see why doing it as a separate thread will improve things. There are N nfsd threads already (N can be bumped up to 256 if you wish) and having a bunch more "cache trimming threads" would just increase contention, wouldn't it? The only negative effect I can think of w.r.t. having the nfsd threads doing it would be a (I believe negligible) increase in RPC response times (the time the nfsd thread spends trimming the cache). As noted, I think this time would be negligible compared to disk I/O and network transit times in the total RPC response time? Isilon did use separate threads (I never saw their code, so I am going by what they told me), but it sounded to me like they were trimming the cache too agressively to be effective for TCP mounts. (ie. It sounded to me like they had broken the algorithm to achieve better perf.) Remember that the DRC is weird, in that it is a cache to improve correctness at the expense of overhead. It never improves performance. On the other hand, turn it off or throw away entries too aggressively and data corruption, due to retries of non-idempotent operations, can be the outcome. Good luck with whatever you choose, rick > It's pretty clear from the profile that the cache mutex is heavily > contended, so anything that reduces the length of time it's held is > probably a win. > > That URL again, for the benefit of people on freebsd-fs who didn't see > it on hackers, is: > > >> <http://people.csail.mit.edu/wollman/nfs-server.unhalted-core-cycles.png>. > > (This graph is slightly modified from my previous post as I removed > some spurious edges to make the formatting look better. Still looking > for a way to get a profile that includes all kernel modules with the > kernel.) > > -GAWollman > _______________________________________________ > freebsd-hackers@freebsd.org mailing list > http://lists.freebsd.org/mailman/listinfo/freebsd-hackers > To unsubscribe, send any mail to > "freebsd-hackers-unsubscribe@freebsd.org"
{kind=link}
Want to link to this message? Use this URL: <https://mail-archive.FreeBSD.org/cgi/mid.cgi?1571646304.1630985.1349270466529.JavaMail.root>