Date: Thu, 2 Mar 2017 19:04:15 +1100 (EST) From: Bruce Evans <brde@optusnet.com.au> To: Conrad Meyer <cem@freebsd.org> Cc: Bruce Evans <brde@optusnet.com.au>, src-committers <src-committers@freebsd.org>, svn-src-all@freebsd.org, svn-src-head@freebsd.org Subject: Re: svn commit: r313006 - in head: sys/conf sys/libkern sys/libkern/x86 sys/sys tests/sys/kern Message-ID: <20170302174554.G10162@besplex.bde.org> In-Reply-To: <CAG6CVpWG3xuNEF%2BRW4DG3HdLb=GgPKwapBLyq-kArRV%2B3fBcfQ@mail.gmail.com> References: <201701310326.v0V3QW30024375@repo.freebsd.org> <20170202184819.GP2092@kib.kiev.ua> <20170203062806.A2690@besplex.bde.org> <CAG6CVpV8fqMd82hjYoyDfO3f5P-x6%2B0OJDoQHtqXqY_tfWtZsA@mail.gmail.com> <20170228121335.Q2733@besplex.bde.org> <CAG6CVpWwZhMAsVB%2Bp-N0fMVOzzQSRaYonEfE-4Z6gv%2BLGuRn9w@mail.gmail.com> <20170302162120.C8136@besplex.bde.org> <CAG6CVpWG3xuNEF%2BRW4DG3HdLb=GgPKwapBLyq-kArRV%2B3fBcfQ@mail.gmail.com>
next in thread | previous in thread | raw e-mail | index | archive | help
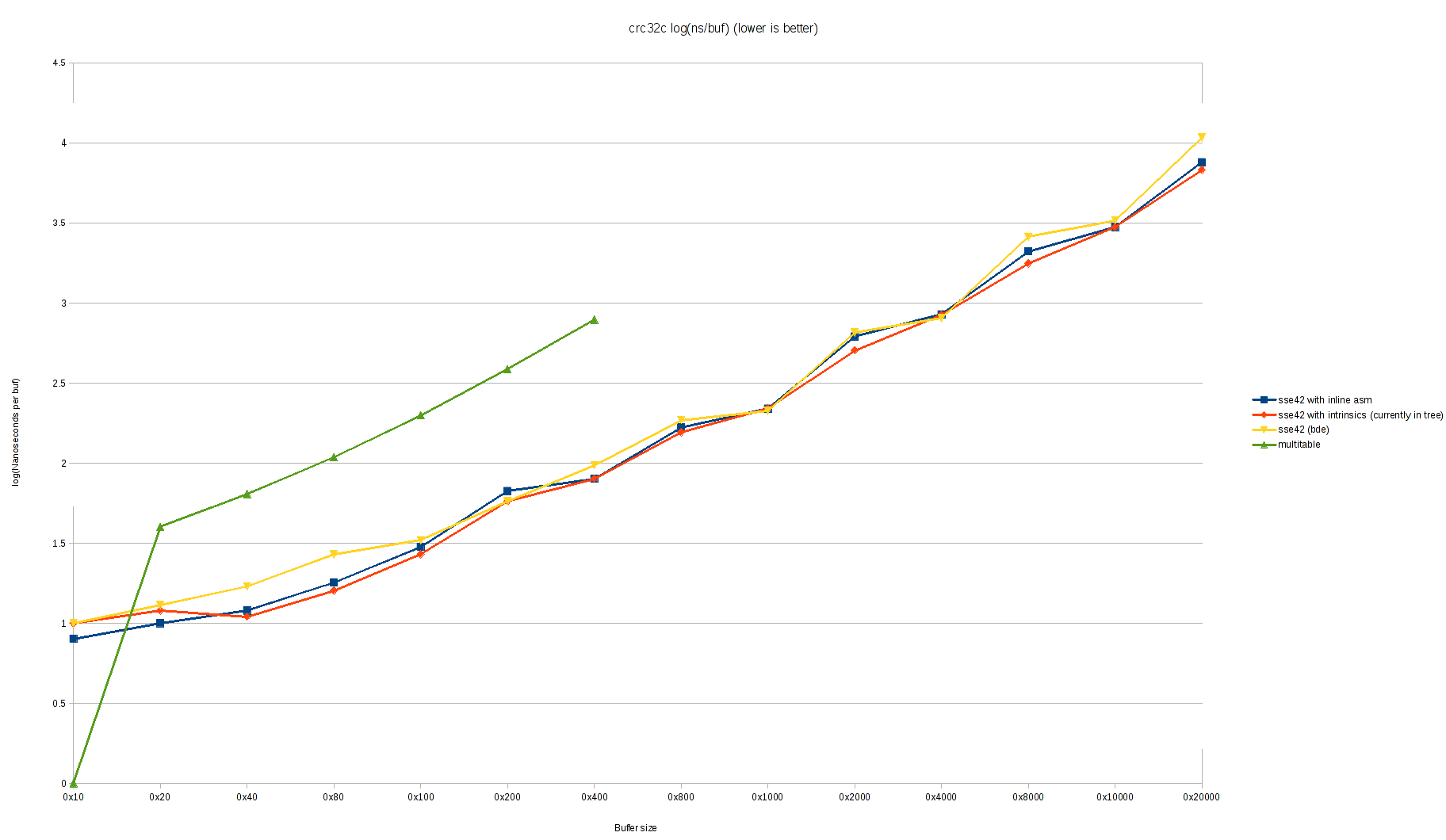
On Wed, 1 Mar 2017, Conrad Meyer wrote: > On Wed, Mar 1, 2017 at 9:27 PM, Bruce Evans <brde@optusnet.com.au> wrote: >> On Wed, 1 Mar 2017, Conrad Meyer wrote: >> >>> On my laptop (Intel(R) Core(TM) i5-3320M CPU =E2=80=94 Ivy Bridge) I st= ill see >>> a little worse performance with this patch. Please excuse the ugly >>> graphs, I don't have a better graphing tool set up at this time: >>> >>> https://people.freebsd.org/~cem/crc32/sse42_bde.png >>> https://people.freebsd.org/~cem/crc32/sse42_bde_log.png >> >> Try doubling the loop sizes. There shouldn't be any significant differe= nce >> above size 3*LONG unless LONG is too small. Apparently it is too small = for >> older CPUs. >> >> I now have a Sandybridge i5-2xxx laptop to test on, but don't have it se= t >> up for much yet. > > Doubling the loop sizes seems to make it slightly worse, actually: > > https://people.freebsd.org/~cem/crc32/sse42_bde2.png > https://people.freebsd.org/~cem/crc32/sse42_bde_log2.png > > I haven't made any attempt to inspect the generated assembly. This is > Clang 3.9.1 with -O2. I tested on Sandybridge (i5=3D2540M) and get exactly the opposite results with clang-3.9-0. It is much slower with intrinsics. Much slower than gcc-4-2.1. Perhaps a bug in one of the test programs (mine is enclosed). Minimum types with low variance (+-10 msec_ for "./z2 size 10" (100G total) in seconds on idle system: buf_size: 512 3*512 4096 3*4096 -------------- ----- ----- ---- ------ =2E/z2-bde-clang 10.57 8.36 6.85 6.58 =2E/z2-bde-gcc 10.99 8.96 7.08 6.58 =2E/z2-cur-clang 17.23 11.19 6.97 6.75 Oops, that was with MISALIGN =3D 1. Also, I forgot to force aligment of bu= f, but checked it was at 0x...40 in all case. Now with proper alignment: buf size: 512 3*512 4096 3*4096 -------------- ----- ----- ---- ------ =2E/z2-bde-clang 8.96 6.56 6.62 6.42 =2E/z2-bde-gcc 8.81 6.51 6.63 6.30 =2E/z2-cur-clang 14.70 6.22 6.66 6.13 The number of iterations is adjusted so that buf_size * num_iter =3D 100G. This shows that clang-3.9.0 with intrinsics is doing lots of rearrangement which is very bad for the misaligned case and otherwise helps for the multiple-of-3 cases (when the SHORT loop is null), and otherwise is a small pessimization relative to no intrinsicts, but beats gcc, while gcc does almost none. (I mostly tested with gcc -O3 and it seemed equally good then.) The function doesn't use __predict_ugly(), and clang apparently uses this to optimized the alignment code at great cost to the main loops when the alignment code executes (perhaps it removes the alignment code?) clang also does poorly with buf_size 512 in the aligned case. Indeed, gcc is much better with -O3 (other flags -static [-msse4 for intrins]). clang does excessive optimizations by default, and -O3 makes no difference for it: buf size: 512 3*512 4096 3*4096 -------------- ----- ----- ---- ------ =2E/z2-bde-clangO3 8.96 6.56 6.62 6.42 =2E/z2-bde-gccO3 8.95 6.06 6.11 5.80 =2E/z2-cur-clangO3 14.70 6.22 6.66 6.13 So we seem to be mainly testing uninteresting compiler pessimizations. Eventually compilers will understand the code better and not rearrange it very much (except for the alignment part). I did a quick test with LONG =3D SHORT =3D 128 and gcc -O2. This was just slower, even for the ideal loop size of 4096*3 (up from 6.30 to 6.67 seconds). This change just removes the LONG loop after renaming the SHORT loop to LONG. gcc apparently thinks it understands this simpler version, and pessimizes it. While testing, I did notice a pessimization that is not the compiler's fault: when the crc32 instructions are optimized at the expense of the crc update at the end of the loop, the loop gets out of sync with the update and the wrong thing can stall. The code has subtleties to try to prevent this, by compilers don't really understand this. Compiler membars to control the ordering precisely were just pessimizations. X #include <stdint.h> X #include <stdio.h> X #include <stdlib.h> X #include <string.h> X=20 X #define MISALIGN=091 X #define SIZE=09=09(1024 * 1024) X=20 X uint8_t buf[MISALIGN + SIZE]; X=20 X uint32_t sse42_crc32c(uint32_t, const unsigned char *, unsigned); X=20 X int X main(int argc, char **argv) X { X =09size_t size; X =09uint32_t crc; X =09int i, j, limit, repeat; X=20 X =09size =3D argc =3D=3D 1 ? SIZE : atoi(argv[1]); X =09limit =3D 10000000000L / size; X =09repeat =3D argc < 3 ? 10 : atoi(argv[2]); X =09for (i =3D 0; i < sizeof(buf); i++) X =09=09buf[i] =3D rand(); X =09crc =3D 0; X =09for (j =3D 0; j < repeat; j++) X =09=09for (i =3D 0; i < limit; i++) X =09=09=09crc =3D sse42_crc32c(crc, &buf[MISALIGN], size); X =09printf("%#x\n", sse42_crc32c(0, &buf[MISALIGN], size)); X =09return (crc =3D=3D 0 ? 0 : 1); X } Loops like this are not very representative of normal use, but I don't know a better way. Bruce From owner-svn-src-all@freebsd.org Thu Mar 2 14:50:03 2017 Return-Path: <owner-svn-src-all@freebsd.org> Delivered-To: svn-src-all@mailman.ysv.freebsd.org Received: from mx1.freebsd.org (mx1.freebsd.org [IPv6:2001:1900:2254:206a::19:1]) by mailman.ysv.freebsd.org (Postfix) with ESMTP id 38465CF47F1; Thu, 2 Mar 2017 14:50:03 +0000 (UTC) (envelope-from des@FreeBSD.org) Received: from repo.freebsd.org (repo.freebsd.org [IPv6:2610:1c1:1:6068::e6a:0]) (using TLSv1.2 with cipher ECDHE-RSA-AES256-GCM-SHA384 (256/256 bits)) (Client did not present a certificate) by mx1.freebsd.org (Postfix) with ESMTPS id 07CA12AE; Thu, 2 Mar 2017 14:50:02 +0000 (UTC) (envelope-from des@FreeBSD.org) Received: from repo.freebsd.org ([127.0.1.37]) by repo.freebsd.org (8.15.2/8.15.2) with ESMTP id v22Eo2lG031736; Thu, 2 Mar 2017 14:50:02 GMT (envelope-from des@FreeBSD.org) Received: (from des@localhost) by repo.freebsd.org (8.15.2/8.15.2/Submit) id v22Eo2l1031735; Thu, 2 Mar 2017 14:50:02 GMT (envelope-from des@FreeBSD.org) Message-Id: <201703021450.v22Eo2l1031735@repo.freebsd.org> X-Authentication-Warning: repo.freebsd.org: des set sender to des@FreeBSD.org using -f From: =?UTF-8?Q?Dag-Erling_Sm=c3=b8rgrav?= <des@FreeBSD.org> Date: Thu, 2 Mar 2017 14:50:02 +0000 (UTC) To: src-committers@freebsd.org, svn-src-all@freebsd.org, svn-src-head@freebsd.org Subject: svn commit: r314554 - head/sbin/md5 X-SVN-Group: head MIME-Version: 1.0 Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: 8bit X-BeenThere: svn-src-all@freebsd.org X-Mailman-Version: 2.1.23 Precedence: list List-Id: "SVN commit messages for the entire src tree \(except for " user" and " projects" \)" <svn-src-all.freebsd.org> List-Unsubscribe: <https://lists.freebsd.org/mailman/options/svn-src-all>, <mailto:svn-src-all-request@freebsd.org?subject=unsubscribe> List-Archive: <http://lists.freebsd.org/pipermail/svn-src-all/>; List-Post: <mailto:svn-src-all@freebsd.org> List-Help: <mailto:svn-src-all-request@freebsd.org?subject=help> List-Subscribe: <https://lists.freebsd.org/mailman/listinfo/svn-src-all>, <mailto:svn-src-all-request@freebsd.org?subject=subscribe> X-List-Received-Date: Thu, 02 Mar 2017 14:50:03 -0000 Author: des Date: Thu Mar 2 14:50:01 2017 New Revision: 314554 URL: https://svnweb.freebsd.org/changeset/base/314554 Log: Fix date. Reported by: delphij, mckay MFC with: r314528 Modified: head/sbin/md5/md5.1 Modified: head/sbin/md5/md5.1 ============================================================================== --- head/sbin/md5/md5.1 Thu Mar 2 12:20:23 2017 (r314553) +++ head/sbin/md5/md5.1 Thu Mar 2 14:50:01 2017 (r314554) @@ -91,7 +91,7 @@ and algorithms have been proven to be vulnerable to practical collision attacks and should not be relied upon to produce unique outputs, nor should they be used as part of a cryptographic signature scheme. -As of 2016-03-02, there is no publicly known method to +As of 2017-03-02, there is no publicly known method to .Em reverse either algorithm, i.e. to find an input that produces a specific output.
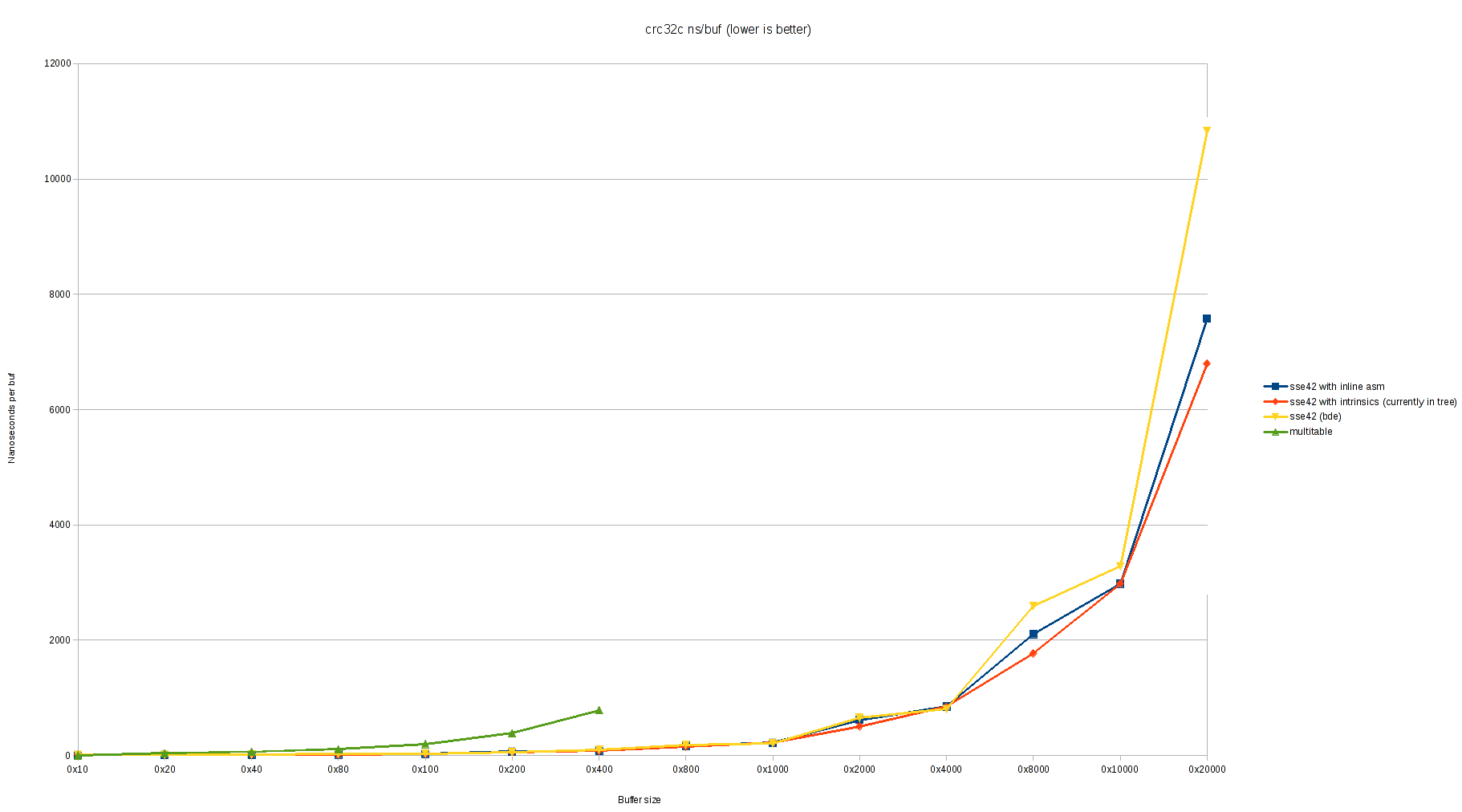{kind=link}
{kind=link}
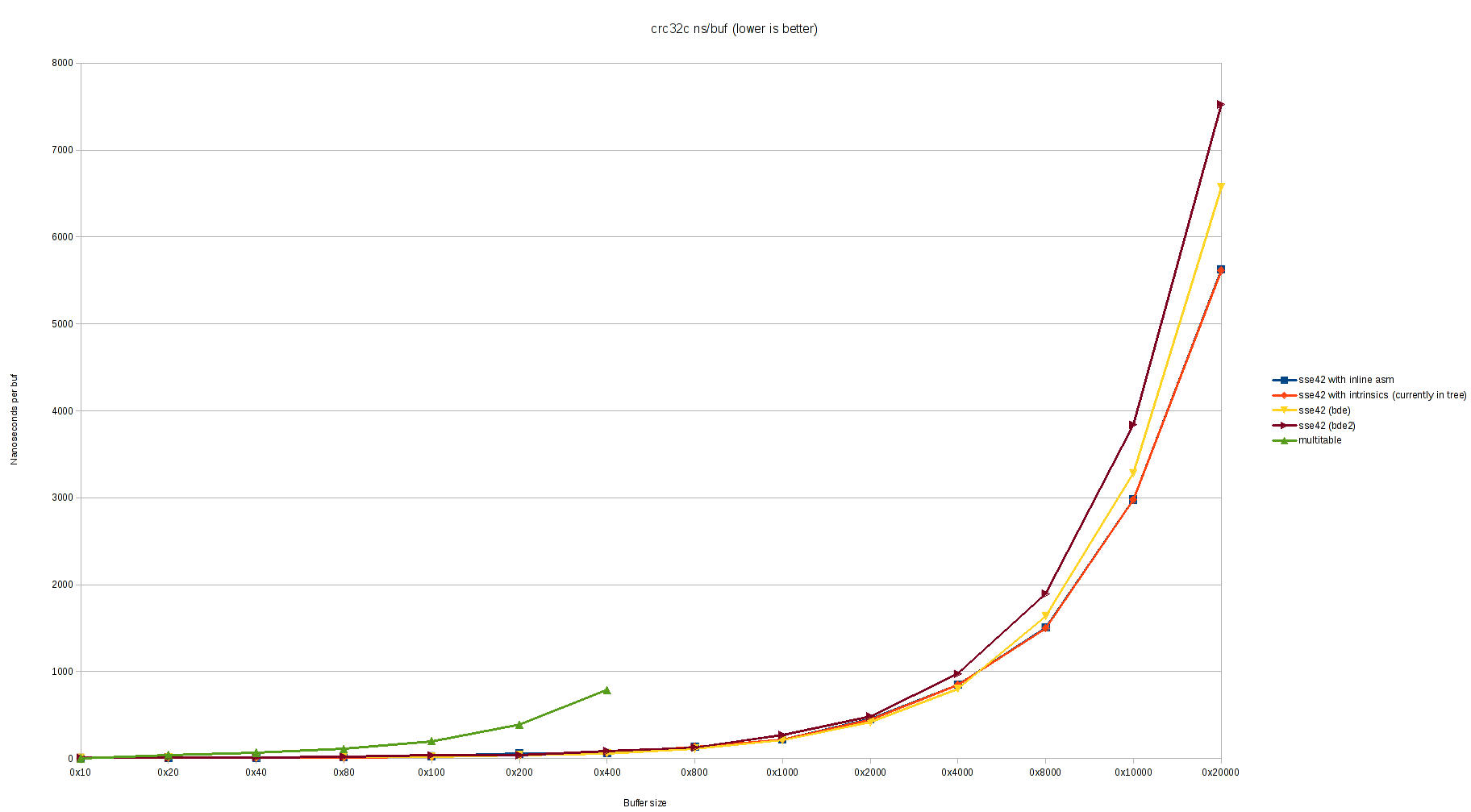{kind=link}
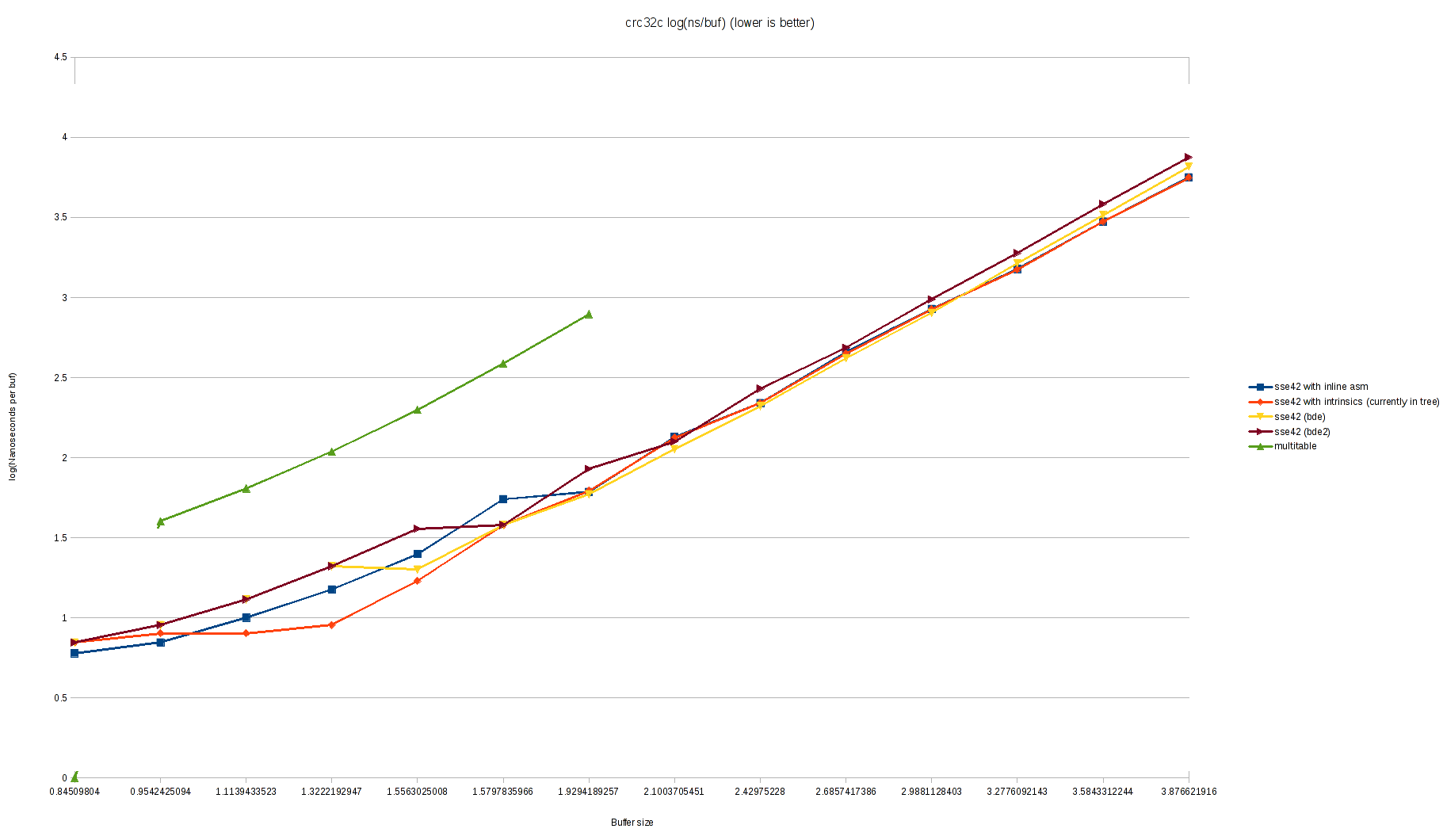{kind=link}
Want to link to this message? Use this URL: <https://mail-archive.FreeBSD.org/cgi/mid.cgi?20170302174554.G10162>