Date: Wed, 30 Dec 2015 09:31:48 -0600 From: Karl Denninger <karl@denninger.net> To: freebsd-fs@freebsd.org Subject: Re: Panic in ZFS during zfs recv (while snapshots being destroyed) Message-ID: <5683F8E4.5090007@denninger.net> In-Reply-To: <562A23B0.4050306@denninger.net> References: <55BB443E.8040801@denninger.net> <55CF7926.1030901@denninger.net> <55DF7191.2080409@denninger.net> <sig.0681f4fd27.ADD991B6-BCF2-4B11-A5D6-EF1DB585AA33@chittenden.org> <55DF76AA.3040103@denninger.net> <561FB7D0.4080107@denninger.net> <562662ED.1070302@denninger.net> <562A23B0.4050306@denninger.net>
next in thread | previous in thread | raw e-mail | index | archive | help
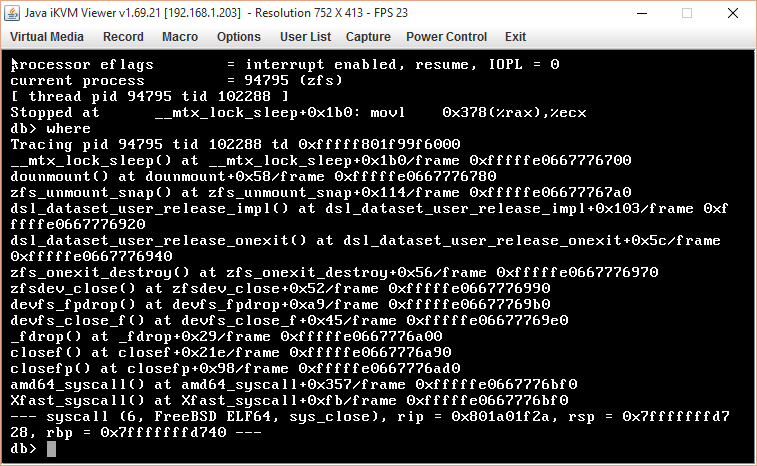
This is a cryptographically signed message in MIME format. --------------ms060309030704010707060405 Content-Type: text/plain; charset=windows-1252 Content-Transfer-Encoding: quoted-printable I believe that the latest change to my patch fixes this both in patched and unpatched systems. https://bugs.freebsd.org/bugzilla/show_bug.cgi?id=3D187594 The root cause appears to be that while it should not be possible for dirty >=3D dirty_data_max in either the patched or unpatched case it in fact can occur, and if it does you get a zero value for the delay computation if the unsigned subtraction underflows (or an outright panic on an integer divide-by-zero attempt.) The latter of course produces an immediate panic but the former corrupts the running system and results in a later panic. Some other reported cases of what I believe is the same problem occurs with a reported divide-by-zero trap but when examining the variables in question the two operands do not result in a difference of zero. I am hesitant to declare that this change fixes it since I cannot provoke the panic "on demand"; it only occurs under heavy filesystem load including snapshot activity in my case, although another reported instance occurred during /etc/periodic runs against a huge number of jails at the same time, and is likely related. But, since putting the change in on 10 December I've not had the sentinels that mark the corrupt state which I had previously identified fire, nor have I had a panic occur. If you've run into a panic in the zfs code during very heavy and unusual use I'd be real interested in whether they stop if you run the last of the above patches; it should apply against 10-STABLE of approximately r289078 or later. Thanks; On 10/23/2015 07:10, Karl Denninger wrote: > While continuing to run this down I think I've managed to duplicate the= > state that produces the panic, but I don't know exactly how or why. > > The script (modified to check all returns) now produced this on a test = case: > > ...... > receiving incremental stream of > zsr/R/10.2-STABLE@zfs-auto-snap_frequent-2015-10-23-04h00 into > backup/R/10.2-STABLE@zfs-auto-snap_frequent-2015-10-23-04h00 > received 559MB stream in 22 seconds (25.4MB/sec) > receiving incremental stream of > zsr/R/10.2-STABLE@zfs-auto-snap_hourly-2015-10-23-04h04 into > backup/R/10.2-STABLE@zfs-auto-snap_hourly-2015-10-23-04h04 > received 4.25MB stream in 1 seconds (4.25MB/sec) > receiving incremental stream of > zsr/R/10.2-STABLE@zfs-auto-snap_frequent-2015-10-23-05h00 into > backup/R/10.2-STABLE@zfs-auto-snap_frequent-2015-10-23-05h00 > received 12.5MB stream in 1 seconds (12.5MB/sec) > receiving incremental stream of > zsr/R/10.2-STABLE@zfs-auto-snap_frequent-2015-10-23-06h00 into > backup/R/10.2-STABLE@zfs-auto-snap_frequent-2015-10-23-06h00 > received 13.4MB stream in 1 seconds (13.4MB/sec) > receiving incremental stream of zsr/R/10.2-STABLE@zfs-base into > backup/R/10.2-STABLE@zfs-base > received 14.8MB stream in 1 seconds (14.8MB/sec) > *will destroy zsr/R/10.2-STABLE@zfs-old** > **will reclaim 6.50M** > **cannot destroy snapshot zsr/R/10.2-STABLE@zfs-old: dataset is busy** > **Snapshot destroy FAILED with code 1* > > And there it stopped, as I have it trapped. > > But, there's nothing holding that dataset open: > > root@NewFS:~ # zfs holds zsr/R/10.2-STABLE@zfs-old > NAME TAG TIMESTAMP > > There is also no send or receive command still running, and an attempt > to force (or defer) the destroy fails too: > > root@NewFS:~ # zfs destroy zsr/R/10.2-STABLE@zfs-old > cannot destroy snapshot zsr/R/10.2-STABLE@zfs-old: dataset is busy > root@NewFS:~ # zfs destroy -d zsr/R/10.2-STABLE@zfs-old > cannot destroy snapshot zsr/R/10.2-STABLE@zfs-old: dataset is busy > root@NewFS:~ # zfs destroy -f zsr/R/10.2-STABLE@zfs-old > cannot destroy snapshot zsr/R/10.2-STABLE@zfs-old: dataset is busy > > Parameters: > > root@NewFS:~ # zfs get all zsr/R/10.2-STABLE@zfs-old > NAME PROPERTY VALUE = =20 > SOURCE > zsr/R/10.2-STABLE@zfs-old type snapshot = - > zsr/R/10.2-STABLE@zfs-old creation Thu Oct 22 10:14 2015= - > zsr/R/10.2-STABLE@zfs-old used 6.50M = - > zsr/R/10.2-STABLE@zfs-old referenced 25.7G = - > zsr/R/10.2-STABLE@zfs-old compressratio 1.86x = - > zsr/R/10.2-STABLE@zfs-old devices on = =20 > default > zsr/R/10.2-STABLE@zfs-old exec on = =20 > default > zsr/R/10.2-STABLE@zfs-old setuid on = =20 > default > zsr/R/10.2-STABLE@zfs-old xattr off = =20 > temporary > zsr/R/10.2-STABLE@zfs-old version 5 = - > zsr/R/10.2-STABLE@zfs-old utf8only off = - > zsr/R/10.2-STABLE@zfs-old normalization none = - > zsr/R/10.2-STABLE@zfs-old casesensitivity sensitive = - > zsr/R/10.2-STABLE@zfs-old nbmand off = =20 > default > zsr/R/10.2-STABLE@zfs-old primarycache all = =20 > default > zsr/R/10.2-STABLE@zfs-old secondarycache all = =20 > default > zsr/R/10.2-STABLE@zfs-old defer_destroy off = - > zsr/R/10.2-STABLE@zfs-old userrefs 0 = - > zsr/R/10.2-STABLE@zfs-old mlslabel = - > zsr/R/10.2-STABLE@zfs-old refcompressratio 1.86x = - > zsr/R/10.2-STABLE@zfs-old written 169M = - > zsr/R/10.2-STABLE@zfs-old clones = - > zsr/R/10.2-STABLE@zfs-old logicalused 0 = - > zsr/R/10.2-STABLE@zfs-old logicalreferenced 42.7G = - > zsr/R/10.2-STABLE@zfs-old volmode default = =20 > default > zsr/R/10.2-STABLE@zfs-old com.sun:auto-snapshot true = =20 > inherited from zsr/R/10.2-STABLE > > Nothing here that looks like a problem; specifically, no clones. > > If I run the script again and it attempts recovery (since zfs-old is > present) the machine panics with the below. Once the machine has > panic'd I can remove the snapshot. > > This looks like some sort of bug internally in the zfs state -- but the= > question is, now that I'm in this state how do I get out without a cras= h > and why did it happen, given that I can't find any reason for the > snapshot to be non-removable (e.g. an active clone, etc) > > Ideas or anything that would help find the source of the problem using = zdb? > > On 10/20/2015 10:51, Karl Denninger wrote: >> More data on this crash from this morning; I caught it in-process this= >> time and know exactly where it was in the backup script when it detona= ted. >> >> Here's the section of the script that was running when it blew up: >> >> for i in $ZFS >> do >> echo Processing $i >> >> FILESYS=3D`echo $i|cut -d/ -f2` >> >> zfs list $i@zfs-base >/dev/null 2>&1 >> result=3D$? >> if [ $result -eq 1 ]; >> then >> echo "Make and send zfs-base snapshot" >> zfs snapshot -r $i@zfs-base >> zfs send -R $i@zfs-base | zfs receive -Fuvd $BACKUP >> else >> base_only=3D`zfs get -H com.backup:base-only $i|grep t= rue` >> result=3D$? >> if [ $result -eq 1 ]; >> then >> echo "Bring incremental backup up to date" >> old_present=3D`zfs list $i@zfs-old >/dev/null = 2>&1` >> old=3D$? >> if [ $old -eq 0 ]; >> then >> echo "Previous incremental sync was >> interrupted; resume" >> else >> zfs rename -r $i@zfs-base $i@zfs-old >> zfs snapshot -r $i@zfs-base >> fi >> zfs send -RI $i@zfs-old $i@zfs-base | zfs >> receive -Fudv $BACKUP >> result=3D$? >> if [ $result -eq 0 ]; >> then >> zfs destroy -r $i@zfs-old >> zfs destroy -r $BACKUP/$FILESYS@zfs-ol= d >> else >> echo "STOP - - ERROR RUNNING COPY on $= i!!!!" >> exit 1 >> fi >> else >> echo "Base-only backup configured for $i" >> fi >> fi >> echo >> done >> >> And the output on the console when it happened: >> >> Begin local ZFS backup by SEND >> Run backups of default [zsr/R/10.2-STABLE zsr/ssd-txlog zs/archive >> zs/colo-archive zs/disk zs/pgsql zs/pics dbms/ticker] >> Tue Oct 20 10:14:09 CDT 2015 >> >> Import backup pool >> Imported; ready to proceed >> Processing zsr/R/10.2-STABLE >> Bring incremental backup up to date >> _*Previous incremental sync was interrupted; resume*_ >> attempting destroy backup/R/10.2-STABLE@zfs-auto-snap_daily-2015-10-13= -00h07 >> success >> attempting destroy >> backup/R/10.2-STABLE@zfs-auto-snap_hourly-2015-10-18-12h04 >> success >> *local fs backup/R/10.2-STABLE does not have fromsnap (zfs-old in stre= am);** >> **must have been deleted locally; ignoring* >> receiving incremental stream of >> zsr/R/10.2-STABLE@zfs-auto-snap_daily-2015-10-18-00h07 into >> backup/R/10.2-STABLE@zfs-auto-snap_daily-2015-10-18-00h07 >> snap backup/R/10.2-STABLE@zfs-auto-snap_daily-2015-10-18-00h07 already= >> exists; ignoring >> received 0B stream in 1 seconds (0B/sec) >> receiving incremental stream of >> zsr/R/10.2-STABLE@zfs-auto-snap_weekly-2015-10-18-00h14 into >> backup/R/10.2-STABLE@zfs-auto-snap_weekly-2015-10-18-00h14 >> snap backup/R/10.2-STABLE@zfs-auto-snap_weekly-2015-10-18-00h14 alread= y >> exists; ignoring >> received 0B stream in 1 seconds (0B/sec) >> receiving incremental stream of zsr/R/10.2-STABLE@zfs-base into >> backup/R/10.2-STABLE@zfs-base >> snap backup/R/10.2-STABLE@zfs-base already exists; ignoring >> >> That bolded pair of lines should _*not*_ be there. It means that the= >> snapshot "zfs-old" is on the source volume, but it shouldn't be there >> because after the copy is complete we destroy it on both the source an= d >> destination. Further, when it is attempted to be sent while the >> snapshot name (zfs-old) was found in a zfs list /*the data allegedly >> associated with the phantom snapshot that shouldn't exist was not ther= e >> */(second bolded line) >> >> zfs send -RI $i@zfs-old $i@zfs-base | zfs >> receive -Fudv $BACKUP >> result=3D$? >> if [ $result -eq 0 ]; >> then >> *zfs destroy -r $i@zfs-old** >> ** zfs destroy -r $BACKUP/$FILESYS@zfs-= old* >> else >> echo "STOP - - ERROR RUNNING COPY on $= i!!!!" >> exit 1 >> fi >> >> I don't have the trace from the last run (I didn't save it) *but there= >> were no errors returned by it *as it was run by hand (from the console= ) >> while I was watching it. >> >> This STRONGLY implies that the zfs destroy /allegedly /succeeded (it r= an >> without an error and actually removed the snapshot) but left the >> snapshot _*name*_ on the volume as it was able to be found by the >> script, and then when that was referenced by the backup script in the >> incremental send the data set was invalid producing the resulting pani= c. >> >> The bad news is that the pool shows no faults and a scrub which took >> place a few days ago says the pool is fine. If I re-run the backup I >> suspect it will properly complete (it always has in the past as a resu= me >> from the interrupted one) but clearly, whatever is going on here looks= >> like some sort of race in the destroy commands (which _*are*_ being ru= n >> recursively) that leaves the snapshot name on the volume but releases >> the data stored in it, thus the panic when it is attempted to be >> referenced. >> >> I have NOT run a scrub on the pool in an attempt to preserve whatever >> evidence may be there; if there is something that I can look at with z= db >> or similar I'll leave this alone for a bit -- the machine came back up= >> and is running fine. >> >> This is a production system but I can take it down off-hours for a sho= rt >> time if there is a need to run something in single-user mode using zdb= >> to try to figure out what's going on. There have been no known hardwa= re >> issues with it and all the other pools (including the ones on the same= >> host adapter) are and have been running without incident. >> >> Ideas? >> >> >> Fatal trap 12: page fault while in kernel mode >> cpuid =3D 9; apic id =3D 21 >> fault virtual address =3D 0x378 >> fault code =3D supervisor read data, page not present >> instruction pointer =3D 0x20:0xffffffff80940ae0 >> stack pointer =3D 0x28:0xfffffe0668018680 >> frame pointer =3D 0x28:0xfffffe0668018700 >> code segment =3D base 0x0, limit 0xfffff, type 0x1b >> =3D DPL 0, pres 1, long 1, def32 0, gran 1 >> processor eflags =3D interrupt enabled, resume, IOPL =3D 0 >> current process =3D 70921 (zfs) >> trap number =3D 12 >> panic: page fault >> cpuid =3D 9 >> KDB: stack backtrace: >> db_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame >> 0xfffffe0668018160 >> kdb_backtrace() at kdb_backtrace+0x39/frame 0xfffffe0668018210 >> vpanic() at vpanic+0x126/frame 0xfffffe0668018250 >> panic() at panic+0x43/frame 0xfffffe06680182b0 >> trap_fatal() at trap_fatal+0x36b/frame 0xfffffe0668018310 >> trap_pfault() at trap_pfault+0x2ed/frame 0xfffffe06680183b0 >> trap() at trap+0x47a/frame 0xfffffe06680185c0 >> calltrap() at calltrap+0x8/frame 0xfffffe06680185c0 >> --- trap 0xc, rip =3D 0xffffffff80940ae0, rsp =3D 0xfffffe0668018680, = rbp =3D >> 0xfffffe0668018700 --- >> *__mtx_lock_sleep() at __mtx_lock_sleep+0x1b0/frame 0xfffffe0668018700= ** >> **dounmount() at dounmount+0x58/frame 0xfffffe0668018780** >> **zfs_unmount_snap() at zfs_unmount_snap+0x114/frame 0xfffffe06680187a= 0** >> **dsl_dataset_user_release_impl() at >> dsl_dataset_user_release_impl+0x103/frame 0xfffffe0668018920** >> **dsl_dataset_user_release_onexit() at >> dsl_dataset_user_release_onexit+0x5c/frame 0xfffffe0668018940** >> **zfs_onexit_destroy() at zfs_onexit_destroy+0x56/frame 0xfffffe066801= 8970** >> **zfsdev_close() at zfsdev_close+0x52/frame 0xfffffe0668018990* >> devfs_fpdrop() at devfs_fpdrop+0xa9/frame 0xfffffe06680189b0 >> devfs_close_f() at devfs_close_f+0x45/frame 0xfffffe06680189e0 >> _fdrop() at _fdrop+0x29/frame 0xfffffe0668018a00 >> closef() at closef+0x21e/frame 0xfffffe0668018a90 >> closefp() at closefp+0x98/frame 0xfffffe0668018ad0 >> amd64_syscall() at amd64_syscall+0x35d/frame 0xfffffe0668018bf0 >> Xfast_syscall() at Xfast_syscall+0xfb/frame 0xfffffe0668018bf0 >> --- syscall (6, FreeBSD ELF64, sys_close), rip =3D 0x801a01f5a, rsp =3D= >> 0x7fffffffd1e8, rbp =3D 0x7fffffffd200 --- >> Uptime: 5d0h58m0s >> >> >> >> On 10/15/2015 09:27, Karl Denninger wrote: >>> Got another one of these this morning, after a long absence... >>> >>> Same symptom -- happened during a backup (send/receive) and it's in >>> the same place -- when the snapshot is unmounted. I have a clean dum= p >>> and this is against a quite-recent checkout, so the >>> most-currently-rolled forward ZFS changes are in this kernel. >>> >>> >>> Fatal trap 12: page fault while in kernel mode >>> cpuid =3D 14; apic id =3D 34 >>> fault virtual address =3D 0x378 >>> fault code =3D supervisor read data, page not present >>> instruction pointer =3D 0x20:0xffffffff80940ae0 >>> stack pointer =3D 0x28:0xfffffe066796c680 >>> frame pointer =3D 0x28:0xfffffe066796c700 >>> code segment =3D base 0x0, limit 0xfffff, type 0x1b >>> =3D DPL 0, pres 1, long 1, def32 0, gran 1 >>> processor eflags =3D interrupt enabled, resume, IOPL =3D 0 >>> current process =3D 81187 (zfs) >>> trap number =3D 12 >>> panic: page fault >>> cpuid =3D 14 >>> KDB: stack backtrace: >>> db_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame >>> 0xfffffe066796c160 >>> kdb_backtrace() at kdb_backtrace+0x39/frame 0xfffffe066796c210 >>> vpanic() at vpanic+0x126/frame 0xfffffe066796c250 >>> panic() at panic+0x43/frame 0xfffffe066796c2b0 >>> trap_fatal() at trap_fatal+0x36b/frame 0xfffffe066796c310 >>> trap_pfault() at trap_pfault+0x2ed/frame 0xfffffe066796c3b0 >>> trap() at trap+0x47a/frame 0xfffffe066796c5c0 >>> calltrap() at calltrap+0x8/frame 0xfffffe066796c5c0 >>> --- trap 0xc, rip =3D 0xffffffff80940ae0, rsp =3D 0xfffffe066796c680,= rbp >>> =3D 0xfffffe >>> 066796c700 --- >>> __mtx_lock_sleep() at __mtx_lock_sleep+0x1b0/frame 0xfffffe066796c700= >>> dounmount() at dounmount+0x58/frame 0xfffffe066796c780 >>> zfs_unmount_snap() at zfs_unmount_snap+0x114/frame 0xfffffe066796c7a0= >>> dsl_dataset_user_release_impl() at >>> dsl_dataset_user_release_impl+0x103/frame 0xf >>> ffffe066796c920 >>> dsl_dataset_user_release_onexit() at >>> dsl_dataset_user_release_onexit+0x5c/frame >>> 0xfffffe066796c940 >>> zfs_onexit_destroy() at zfs_onexit_destroy+0x56/frame 0xfffffe066796c= 970 >>> zfsdev_close() at zfsdev_close+0x52/frame 0xfffffe066796c990 >>> devfs_fpdrop() at devfs_fpdrop+0xa9/frame 0xfffffe066796c9b0 >>> devfs_close_f() at devfs_close_f+0x45/frame 0xfffffe066796c9e0 >>> _fdrop() at _fdrop+0x29/frame 0xfffffe066796ca00 >>> closef() at closef+0x21e/frame 0xfffffe066796ca90 >>> closefp() at closefp+0x98/frame 0xfffffe066796cad0 >>> amd64_syscall() at amd64_syscall+0x35d/frame 0xfffffe066796cbf0 >>> Xfast_syscall() at Xfast_syscall+0xfb/frame 0xfffffe066796cbf0 >>> --- syscall (6, FreeBSD ELF64, sys_close), rip =3D 0x801a01f5a, rsp =3D= >>> 0x7fffffffd728, rbp =3D 0x7fffffffd740 --- >>> Uptime: 3d15h37m26s >>> >>> >>> On 8/27/2015 15:44, Karl Denninger wrote: >>>> No, but that does sound like it might be involved..... >>>> >>>> And yeah, this did start when I moved the root pool to a mirrored pa= ir >>>> of Intel 530s off a pair of spinning-rust WD RE4s.... (The 530s are = darn >>>> nice performance-wise, reasonably inexpensive and thus very suitable= for >>>> a root filesystem drive and they also pass the "pull the power cord"= >>>> test, incidentally.) >>>> >>>> You may be onto something -- I'll try shutting it off, but due to th= e >>>> fact that I can't make this happen and it's a "every week or two" pa= nic, >>>> but ALWAYS when the zfs send | zfs recv is running AND it's always o= n >>>> the same filesystem it will be a fair while before I know if it's fi= xed >>>> (like over a month, given the usual pattern here, as that would be 4= >>>> "average" periods without a panic)..... >>>> >>>> I also wonder if I could tune this out with some of the other TRIM >>>> parameters instead of losing it entirely. >>>> >>>> vfs.zfs.trim.max_interval: 1 >>>> vfs.zfs.trim.timeout: 30 >>>> vfs.zfs.trim.txg_delay: 32 >>>> vfs.zfs.trim.enabled: 1 >>>> vfs.zfs.vdev.trim_max_pending: 10000 >>>> vfs.zfs.vdev.trim_max_active: 64 >>>> vfs.zfs.vdev.trim_min_active: 1 >>>> >>>> That it's panic'ing on a mtx_lock_sleep might point this way.... the= >>>> trace shows it coming from a zfs_onexit_destroy, which ends up calli= ng >>>> zfs_unmount_snap() and then it blows in dounmount() while executing >>>> mtx_lock_sleep(). >>>> >>>> I do wonder if I'm begging for new and innovative performance issues= if >>>> I run with TRIM off for an extended period of time, however..... :-)= >>>> >>>> >>>> On 8/27/2015 15:30, Sean Chittenden wrote: >>>>> Have you tried disabling TRIM? We recently ran in to an issue wher= e a `zfs delete` on a large dataset caused the host to panic because TRIM= was tripping over the ZFS deadman timer. Disabling TRIM worked as vali= d workaround for us. ? You mentioned a recent move to SSDs, so this can= happen, esp after the drive has experienced a little bit of actual work.= ? -sc >>>>> >>>>> >>>>> -- >>>>> Sean Chittenden >>>>> sean@chittenden.org >>>>> >>>>> >>>>>> On Aug 27, 2015, at 13:22, Karl Denninger <karl@denninger.net> wro= te: >>>>>> >>>>>> On 8/15/2015 12:38, Karl Denninger wrote: >>>>>>> Update: >>>>>>> >>>>>>> This /appears /to be related to attempting to send or receive a >>>>>>> /cloned /snapshot. >>>>>>> >>>>>>> I use /beadm /to manage boot environments and the crashes have al= l >>>>>>> come while send/recv-ing the root pool, which is the one where th= ese >>>>>>> clones get created. It is /not /consistent within a given snapsh= ot >>>>>>> when it crashes and a second attempt (which does a "recovery" >>>>>>> send/receive) succeeds every time -- I've yet to have it panic tw= ice >>>>>>> sequentially. >>>>>>> >>>>>>> I surmise that the problem comes about when a file in the cloned >>>>>>> snapshot is modified, but this is a guess at this point. >>>>>>> >>>>>>> I'm going to try to force replication of the problem on my test s= ystem. >>>>>>> >>>>>>> On 7/31/2015 04:47, Karl Denninger wrote: >>>>>>>> I have an automated script that runs zfs send/recv copies to bri= ng a >>>>>>>> backup data set into congruence with the running copies nightly.= The >>>>>>>> source has automated snapshots running on a fairly frequent basi= s >>>>>>>> through zfs-auto-snapshot. >>>>>>>> >>>>>>>> Recently I have started having a panic show up about once a week= during >>>>>>>> the backup run, but it's inconsistent. It is in the same place,= but I >>>>>>>> cannot force it to repeat. >>>>>>>> >>>>>>>> The trap itself is a page fault in kernel mode in the zfs code a= t >>>>>>>> zfs_unmount_snap(); here's the traceback from the kvm (sorry for= the >>>>>>>> image link but I don't have a better option right now.) >>>>>>>> >>>>>>>> I'll try to get a dump, this is a production machine with encryp= ted swap >>>>>>>> so it's not normally turned on. >>>>>>>> >>>>>>>> Note that the pool that appears to be involved (the backup pool)= has >>>>>>>> passed a scrub and thus I would assume the on-disk structure is = ok..... >>>>>>>> but that might be an unfair assumption. It is always occurring = in the >>>>>>>> same dataset although there are a half-dozen that are sync'd -- = if this >>>>>>>> one (the first one) successfully completes during the run then a= ll the >>>>>>>> rest will as well (that is, whenever I restart the process it ha= s always >>>>>>>> failed here.) The source pool is also clean and passes a scrub.= >>>>>>>> >>>>>>>> traceback is at http://www.denninger.net/kvmimage.png; apologies= for the >>>>>>>> image traceback but this is coming from a remote KVM. >>>>>>>> >>>>>>>> I first saw this on 10.1-STABLE and it is still happening on Fre= eBSD >>>>>>>> 10.2-PRERELEASE #9 r285890M, which I updated to in an attempt to= see if >>>>>>>> the problem was something that had been addressed. >>>>>>>> >>>>>>>> >>>>>>> --=20 >>>>>>> Karl Denninger >>>>>>> karl@denninger.net <mailto:karl@denninger.net> >>>>>>> /The Market Ticker/ >>>>>>> /[S/MIME encrypted email preferred]/ >>>>>> Second update: I have now taken another panic on 10.2-Stable, same= deal, >>>>>> but without any cloned snapshots in the source image. I had though= t that >>>>>> removing cloned snapshots might eliminate the issue; that is now o= ut the >>>>>> window. >>>>>> >>>>>> It ONLY happens on this one filesystem (the root one, incidentally= ) >>>>>> which is fairly-recently created as I moved this machine from spin= ning >>>>>> rust to SSDs for the OS and root pool -- and only when it is being= >>>>>> backed up by using zfs send | zfs recv (with the receive going to = a >>>>>> different pool in the same machine.) I have yet to be able to pro= voke >>>>>> it when using zfs send to copy to a different machine on the same = LAN, >>>>>> but given that it is not able to be reproduced on demand I can't b= e >>>>>> certain it's timing related (e.g. performance between the two pool= s in >>>>>> question) or just that I haven't hit the unlucky combination. >>>>>> >>>>>> This looks like some sort of race condition and I will continue to= see >>>>>> if I can craft a case to make it occur "on demand" >>>>>> >>>>>> --=20 >>>>>> Karl Denninger >>>>>> karl@denninger.net <mailto:karl@denninger.net> >>>>>> /The Market Ticker/ >>>>>> /[S/MIME encrypted email preferred]/ >>>>> %SPAMBLOCK-SYS: Matched [+Sean Chittenden <sean@chittenden.org>], m= essage ok >>>>> >>> --=20 >>> Karl Denninger >>> karl@denninger.net <mailto:karl@denninger.net> >>> /The Market Ticker/ >>> /[S/MIME encrypted email preferred]/ --=20 Karl Denninger karl@denninger.net <mailto:karl@denninger.net> /The Market Ticker/ /[S/MIME encrypted email preferred]/ --------------ms060309030704010707060405 Content-Type: application/pkcs7-signature; name="smime.p7s" Content-Transfer-Encoding: base64 Content-Disposition: attachment; filename="smime.p7s" Content-Description: S/MIME Cryptographic Signature MIAGCSqGSIb3DQEHAqCAMIACAQExDzANBglghkgBZQMEAgMFADCABgkqhkiG9w0BBwEAAKCC Bl8wggZbMIIEQ6ADAgECAgEpMA0GCSqGSIb3DQEBCwUAMIGQMQswCQYDVQQGEwJVUzEQMA4G A1UECBMHRmxvcmlkYTESMBAGA1UEBxMJTmljZXZpbGxlMRkwFwYDVQQKExBDdWRhIFN5c3Rl bXMgTExDMRwwGgYDVQQDExNDdWRhIFN5c3RlbXMgTExDIENBMSIwIAYJKoZIhvcNAQkBFhND dWRhIFN5c3RlbXMgTExDIENBMB4XDTE1MDQyMTAyMjE1OVoXDTIwMDQxOTAyMjE1OVowWjEL MAkGA1UEBhMCVVMxEDAOBgNVBAgTB0Zsb3JpZGExGTAXBgNVBAoTEEN1ZGEgU3lzdGVtcyBM TEMxHjAcBgNVBAMTFUthcmwgRGVubmluZ2VyIChPQ1NQKTCCAiIwDQYJKoZIhvcNAQEBBQAD ggIPADCCAgoCggIBALmEWPhAdphrWd4K5VTvE5pxL3blRQPyGF3ApjUjgtavqU1Y8pbI3Byg XDj2/Uz9Si8XVj/kNbKEjkRh5SsNvx3Fc0oQ1uVjyCq7zC/kctF7yLzQbvWnU4grAPZ3IuAp 3/fFxIVaXpxEdKmyZAVDhk9az+IgHH43rdJRIMzxJ5vqQMb+n2EjadVqiGPbtG9aZEImlq7f IYDTnKyToi23PAnkPwwT+q1IkI2DTvf2jzWrhLR5DTX0fUYC0nxlHWbjgpiapyJWtR7K2YQO aevQb/3vN9gSojT2h+cBem7QIj6U69rEYcEDvPyCMXEV9VcXdcmW42LSRsPvZcBHFkWAJqMZ Myiz4kumaP+s+cIDaXitR/szoqDKGSHM4CPAZV9Yh8asvxQL5uDxz5wvLPgS5yS8K/o7zDR5 vNkMCyfYQuR6PAJxVOk5Arqvj9lfP3JSVapwbr01CoWDBkpuJlKfpQIEeC/pcCBKknllbMYq yHBO2TipLyO5Ocd1nhN/nOsO+C+j31lQHfOMRZaPQykXVPWG5BbhWT7ttX4vy5hOW6yJgeT/ o3apynlp1cEavkQRS8uJHoQszF6KIrQMID/JfySWvVQ4ksnfzwB2lRomrdrwnQ4eG/HBS+0l eozwOJNDIBlAP+hLe8A5oWZgooIIK/SulUAsfI6Sgd8dTZTTYmlhAgMBAAGjgfQwgfEwNwYI KwYBBQUHAQEEKzApMCcGCCsGAQUFBzABhhtodHRwOi8vY3VkYXN5c3RlbXMubmV0Ojg4ODgw CQYDVR0TBAIwADARBglghkgBhvhCAQEEBAMCBaAwCwYDVR0PBAQDAgXgMCwGCWCGSAGG+EIB DQQfFh1PcGVuU1NMIEdlbmVyYXRlZCBDZXJ0aWZpY2F0ZTAdBgNVHQ4EFgQUxRyULenJaFwX RtT79aNmIB/u5VkwHwYDVR0jBBgwFoAUJHGbnYV9/N3dvbDKkpQDofrTbTUwHQYDVR0RBBYw FIESa2FybEBkZW5uaW5nZXIubmV0MA0GCSqGSIb3DQEBCwUAA4ICAQBPf3cYtmKowmGIYsm6 eBinJu7QVWvxi1vqnBz3KE+HapqoIZS8/PolB/hwiY0UAE1RsjBJ7yEjihVRwummSBvkoOyf G30uPn4yg4vbJkR9lTz8d21fPshWETa6DBh2jx2Qf13LZpr3Pj2fTtlu6xMYKzg7cSDgd2bO sJGH/rcvva9Spkx5Vfq0RyOrYph9boshRN3D4tbWgBAcX9POdXCVfJONDxhfBuPHsJ6vEmPb An+XL5Yl26XYFPiODQ+Qbk44Ot1kt9s7oS3dVUrh92Qv0G3J3DF+Vt6C15nED+f+bk4gScu+ JHT7RjEmfa18GT8DcT//D1zEke1Ymhb41JH+GyZchDRWtjxsS5OBFMzrju7d264zJUFtX7iJ 3xvpKN7VcZKNtB6dLShj3v/XDsQVQWXmR/1YKWZ93C3LpRs2Y5nYdn6gEOpL/WfQFThtfnat HNc7fNs5vjotaYpBl5H8+VCautKbGOs219uQbhGZLYTv6okuKcY8W+4EJEtK0xB08vqr9Jd0 FS9MGjQE++GWo+5eQxFt6nUENHbVYnsr6bYPQsZH0CRNycgTG9MwY/UIXOf4W034UpR82TBG 1LiMsYfb8ahQJhs3wdf1nzipIjRwoZKT1vGXh/cj3gwSr64GfenURBxaFZA5O1acOZUjPrRT n3ci4McYW/0WVVA3lDGCBRMwggUPAgEBMIGWMIGQMQswCQYDVQQGEwJVUzEQMA4GA1UECBMH RmxvcmlkYTESMBAGA1UEBxMJTmljZXZpbGxlMRkwFwYDVQQKExBDdWRhIFN5c3RlbXMgTExD MRwwGgYDVQQDExNDdWRhIFN5c3RlbXMgTExDIENBMSIwIAYJKoZIhvcNAQkBFhNDdWRhIFN5 c3RlbXMgTExDIENBAgEpMA0GCWCGSAFlAwQCAwUAoIICTTAYBgkqhkiG9w0BCQMxCwYJKoZI hvcNAQcBMBwGCSqGSIb3DQEJBTEPFw0xNTEyMzAxNTMxNDhaME8GCSqGSIb3DQEJBDFCBEAu /NcekvOiJzvDSzExhY7Nna6q42VWC3RLfsmEsa3g+C8GnwkwokmpghJsME/LOPyMqF/ef4dK L6c5p9Y5RfzVMGwGCSqGSIb3DQEJDzFfMF0wCwYJYIZIAWUDBAEqMAsGCWCGSAFlAwQBAjAK BggqhkiG9w0DBzAOBggqhkiG9w0DAgICAIAwDQYIKoZIhvcNAwICAUAwBwYFKw4DAgcwDQYI KoZIhvcNAwICASgwgacGCSsGAQQBgjcQBDGBmTCBljCBkDELMAkGA1UEBhMCVVMxEDAOBgNV BAgTB0Zsb3JpZGExEjAQBgNVBAcTCU5pY2V2aWxsZTEZMBcGA1UEChMQQ3VkYSBTeXN0ZW1z IExMQzEcMBoGA1UEAxMTQ3VkYSBTeXN0ZW1zIExMQyBDQTEiMCAGCSqGSIb3DQEJARYTQ3Vk YSBTeXN0ZW1zIExMQyBDQQIBKTCBqQYLKoZIhvcNAQkQAgsxgZmggZYwgZAxCzAJBgNVBAYT AlVTMRAwDgYDVQQIEwdGbG9yaWRhMRIwEAYDVQQHEwlOaWNldmlsbGUxGTAXBgNVBAoTEEN1 ZGEgU3lzdGVtcyBMTEMxHDAaBgNVBAMTE0N1ZGEgU3lzdGVtcyBMTEMgQ0ExIjAgBgkqhkiG 9w0BCQEWE0N1ZGEgU3lzdGVtcyBMTEMgQ0ECASkwDQYJKoZIhvcNAQEBBQAEggIAnt3jAMQb GQFrwzseDKuApQz2F5kZ4FxJ7Y0fhH12F+MwBI6c4F5+b1vMJ6TIR0yTek3uXdFZKyhwe3WH XS7GQx+wXGeG+6EKAi04DczyfeNMiVXFBV3RcGYn1aTSwutAaXT5wMd9ewzA7jAPGIIDCIYx uqd1G2yXNDi5j4nAAOOS8DhukTZ1HEqtCyJvcrGtDQxMfDz5qjMJRgGD01S8e94qyRd/avKC VZ06xqBIWzwZMb/ej4exqgAby6WbO2SAcHYKjVOuNCg8E1i4OP6Oto6pz81daSm/84hN3XX2 9o8tshhfTbw0JIcXu/TY4nnSvdyGtGnR89gC8VjC+8cLLDtjoweykAo3kNPDVdJfHZABRuD0 BSuI3utmQ2pSNh0uJn/rl2NnLOAxvBzjaxkcwPPoudLRVMJG8RnqHY2YT5OK7CFS0Mm0xmac 0JoxIF1rro84hwLErgtqKlwz5bppzLgca8X/JDnWXSPQx5LrJhC30cTontUwSx02iDUDzLnD 1rG5x/cJ7XqAau1oOdskSXQ+2qKMOX2t8QlmXW5GmQErzXsOwC+cgSqYfHoer+EzpM6iOK59 1JbQsh+vDjDTdMbwA/pT9BR4CFmaFUpoHZIljOjErQs3ERiwnAXizMQEv2f7qVzD2hRkfYyB 5kZ7woU8JHRoN84uwCK8+z2rKM4AAAAAAAA= --------------ms060309030704010707060405--
{kind=link}
Want to link to this message? Use this URL: <https://mail-archive.FreeBSD.org/cgi/mid.cgi?5683F8E4.5090007>