
Date: Thu, 15 Oct 2015 09:56:21 -0500 From: Karl Denninger <karl@denninger.net> To: freebsd-fs@freebsd.org Subject: Re: Panic in ZFS during zfs recv (while snapshots being destroyed) Message-ID: <561FBE95.6010107@denninger.net> In-Reply-To: <561FB7D0.4080107@denninger.net> References: <55BB443E.8040801@denninger.net> <55CF7926.1030901@denninger.net> <55DF7191.2080409@denninger.net> <sig.0681f4fd27.ADD991B6-BCF2-4B11-A5D6-EF1DB585AA33@chittenden.org> <55DF76AA.3040103@denninger.net> <561FB7D0.4080107@denninger.net>
next in thread | previous in thread | raw e-mail | index | archive | help
[-- Attachment #1 --]
More data on this -- it is happening during this sequence (snippet from
my backup scripts w/my comments)
"$i" is the ZFS filesystem that is being backed up; in each case the
crashes occur _*only*_ when the root (mounted) filesystem is being
copied; it has never happened on any of the other datasets.
zfs rename -r $i@zfs-base $i@zfs-old (rename the previous backup base
to the "start" point)
zfs snapshot -r $i@zfs-base (take a snapshot to checkpoint to on the backup)
zfs send -RI $i@zfs-old $i@zfs-base | zfs receive -Fudv $BACKUP
result=$?
if [ $result -eq 0 ];
then
_*zfs destroy -r $i@zfs-old*_ -->> *PANIC OCCURS HERE*
zfs destroy -r $BACKUP/$FILESYS@zfs-old
else
echo "STOP - - ERROR RUNNING COPY on $i!!!!"
exit 1
fi
On 10/15/2015 09:27, Karl Denninger wrote:
> Got another one of these this morning, after a long absence...
>
> Same symptom -- happened during a backup (send/receive) and it's in
> the same place -- when the snapshot is unmounted and destroyed. I
> have a clean dump and this is against a quite-recent checkout, so the
> most-currently-rolled forward ZFS changes are in this kernel.
>
>
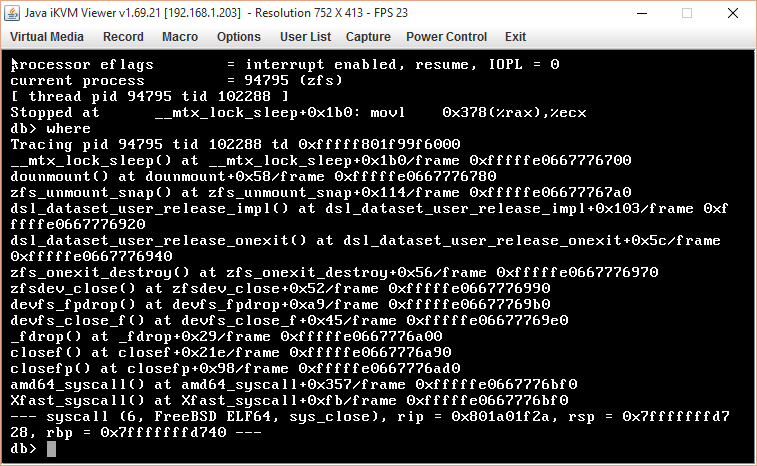
> Fatal trap 12: page fault while in kernel mode
> cpuid = 14; apic id = 34
> fault virtual address = 0x378
> fault code = supervisor read data, page not present
> instruction pointer = 0x20:0xffffffff80940ae0
> stack pointer = 0x28:0xfffffe066796c680
> frame pointer = 0x28:0xfffffe066796c700
> code segment = base 0x0, limit 0xfffff, type 0x1b
> = DPL 0, pres 1, long 1, def32 0, gran 1
> processor eflags = interrupt enabled, resume, IOPL = 0
> current process = 81187 (zfs)
> trap number = 12
> panic: page fault
> cpuid = 14
> KDB: stack backtrace:
> db_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame
> 0xfffffe066796c160
> kdb_backtrace() at kdb_backtrace+0x39/frame 0xfffffe066796c210
> vpanic() at vpanic+0x126/frame 0xfffffe066796c250
> panic() at panic+0x43/frame 0xfffffe066796c2b0
> trap_fatal() at trap_fatal+0x36b/frame 0xfffffe066796c310
> trap_pfault() at trap_pfault+0x2ed/frame 0xfffffe066796c3b0
> trap() at trap+0x47a/frame 0xfffffe066796c5c0
> calltrap() at calltrap+0x8/frame 0xfffffe066796c5c0
> --- trap 0xc, rip = 0xffffffff80940ae0, rsp = 0xfffffe066796c680, rbp
> = 0xfffffe
> 066796c700 ---
> *__mtx_lock_sleep() at __mtx_lock_sleep+0x1b0/frame 0xfffffe066796c700*
> dounmount() at dounmount+0x58/frame 0xfffffe066796c780
> zfs_unmount_snap() at zfs_unmount_snap+0x114/frame 0xfffffe066796c7a0
> dsl_dataset_user_release_impl() at
> dsl_dataset_user_release_impl+0x103/frame 0xf
> ffffe066796c920
> dsl_dataset_user_release_onexit() at
> dsl_dataset_user_release_onexit+0x5c/frame
> 0xfffffe066796c940
> zfs_onexit_destroy() at zfs_onexit_destroy+0x56/frame 0xfffffe066796c970
> zfsdev_close() at zfsdev_close+0x52/frame 0xfffffe066796c990
> devfs_fpdrop() at devfs_fpdrop+0xa9/frame 0xfffffe066796c9b0
> devfs_close_f() at devfs_close_f+0x45/frame 0xfffffe066796c9e0
> _fdrop() at _fdrop+0x29/frame 0xfffffe066796ca00
> closef() at closef+0x21e/frame 0xfffffe066796ca90
> closefp() at closefp+0x98/frame 0xfffffe066796cad0
> amd64_syscall() at amd64_syscall+0x35d/frame 0xfffffe066796cbf0
> Xfast_syscall() at Xfast_syscall+0xfb/frame 0xfffffe066796cbf0
> --- syscall (6, FreeBSD ELF64, sys_close), rip = 0x801a01f5a, rsp =
> 0x7fffffffd728, rbp = 0x7fffffffd740 ---
> Uptime: 3d15h37m26s
>
>
> On 8/27/2015 15:44, Karl Denninger wrote:
>> No, but that does sound like it might be involved.....
>>
>> And yeah, this did start when I moved the root pool to a mirrored pair
>> of Intel 530s off a pair of spinning-rust WD RE4s.... (The 530s are darn
>> nice performance-wise, reasonably inexpensive and thus very suitable for
>> a root filesystem drive and they also pass the "pull the power cord"
>> test, incidentally.)
>>
>> You may be onto something -- I'll try shutting it off, but due to the
>> fact that I can't make this happen and it's a "every week or two" panic,
>> but ALWAYS when the zfs send | zfs recv is running AND it's always on
>> the same filesystem it will be a fair while before I know if it's fixed
>> (like over a month, given the usual pattern here, as that would be 4
>> "average" periods without a panic).....
>>
>> I also wonder if I could tune this out with some of the other TRIM
>> parameters instead of losing it entirely.
>>
>> vfs.zfs.trim.max_interval: 1
>> vfs.zfs.trim.timeout: 30
>> vfs.zfs.trim.txg_delay: 32
>> vfs.zfs.trim.enabled: 1
>> vfs.zfs.vdev.trim_max_pending: 10000
>> vfs.zfs.vdev.trim_max_active: 64
>> vfs.zfs.vdev.trim_min_active: 1
>>
>> That it's panic'ing on a mtx_lock_sleep might point this way.... the
>> trace shows it coming from a zfs_onexit_destroy, which ends up calling
>> zfs_unmount_snap() and then it blows in dounmount() while executing
>> mtx_lock_sleep().
>>
>> I do wonder if I'm begging for new and innovative performance issues if
>> I run with TRIM off for an extended period of time, however..... :-)
>>
>>
>> On 8/27/2015 15:30, Sean Chittenden wrote:
>>> Have you tried disabling TRIM? We recently ran in to an issue where a `zfs delete` on a large dataset caused the host to panic because TRIM was tripping over the ZFS deadman timer. Disabling TRIM worked as valid workaround for us. ? You mentioned a recent move to SSDs, so this can happen, esp after the drive has experienced a little bit of actual work. ? -sc
>>>
>>>
>>> --
>>> Sean Chittenden
>>> sean@chittenden.org
>>>
>>>
>>>> On Aug 27, 2015, at 13:22, Karl Denninger <karl@denninger.net> wrote:
>>>>
>>>> On 8/15/2015 12:38, Karl Denninger wrote:
>>>>> Update:
>>>>>
>>>>> This /appears /to be related to attempting to send or receive a
>>>>> /cloned /snapshot.
>>>>>
>>>>> I use /beadm /to manage boot environments and the crashes have all
>>>>> come while send/recv-ing the root pool, which is the one where these
>>>>> clones get created. It is /not /consistent within a given snapshot
>>>>> when it crashes and a second attempt (which does a "recovery"
>>>>> send/receive) succeeds every time -- I've yet to have it panic twice
>>>>> sequentially.
>>>>>
>>>>> I surmise that the problem comes about when a file in the cloned
>>>>> snapshot is modified, but this is a guess at this point.
>>>>>
>>>>> I'm going to try to force replication of the problem on my test system.
>>>>>
>>>>> On 7/31/2015 04:47, Karl Denninger wrote:
>>>>>> I have an automated script that runs zfs send/recv copies to bring a
>>>>>> backup data set into congruence with the running copies nightly. The
>>>>>> source has automated snapshots running on a fairly frequent basis
>>>>>> through zfs-auto-snapshot.
>>>>>>
>>>>>> Recently I have started having a panic show up about once a week during
>>>>>> the backup run, but it's inconsistent. It is in the same place, but I
>>>>>> cannot force it to repeat.
>>>>>>
>>>>>> The trap itself is a page fault in kernel mode in the zfs code at
>>>>>> zfs_unmount_snap(); here's the traceback from the kvm (sorry for the
>>>>>> image link but I don't have a better option right now.)
>>>>>>
>>>>>> I'll try to get a dump, this is a production machine with encrypted swap
>>>>>> so it's not normally turned on.
>>>>>>
>>>>>> Note that the pool that appears to be involved (the backup pool) has
>>>>>> passed a scrub and thus I would assume the on-disk structure is ok.....
>>>>>> but that might be an unfair assumption. It is always occurring in the
>>>>>> same dataset although there are a half-dozen that are sync'd -- if this
>>>>>> one (the first one) successfully completes during the run then all the
>>>>>> rest will as well (that is, whenever I restart the process it has always
>>>>>> failed here.) The source pool is also clean and passes a scrub.
>>>>>>
>>>>>> traceback is at http://www.denninger.net/kvmimage.png; apologies for the
>>>>>> image traceback but this is coming from a remote KVM.
>>>>>>
>>>>>> I first saw this on 10.1-STABLE and it is still happening on FreeBSD
>>>>>> 10.2-PRERELEASE #9 r285890M, which I updated to in an attempt to see if
>>>>>> the problem was something that had been addressed.
>>>>>>
>>>>>>
>>>>> --
>>>>> Karl Denninger
>>>>> karl@denninger.net <mailto:karl@denninger.net>
>>>>> /The Market Ticker/
>>>>> /[S/MIME encrypted email preferred]/
>>>> Second update: I have now taken another panic on 10.2-Stable, same deal,
>>>> but without any cloned snapshots in the source image. I had thought that
>>>> removing cloned snapshots might eliminate the issue; that is now out the
>>>> window.
>>>>
>>>> It ONLY happens on this one filesystem (the root one, incidentally)
>>>> which is fairly-recently created as I moved this machine from spinning
>>>> rust to SSDs for the OS and root pool -- and only when it is being
>>>> backed up by using zfs send | zfs recv (with the receive going to a
>>>> different pool in the same machine.) I have yet to be able to provoke
>>>> it when using zfs send to copy to a different machine on the same LAN,
>>>> but given that it is not able to be reproduced on demand I can't be
>>>> certain it's timing related (e.g. performance between the two pools in
>>>> question) or just that I haven't hit the unlucky combination.
>>>>
>>>> This looks like some sort of race condition and I will continue to see
>>>> if I can craft a case to make it occur "on demand"
>>>>
>>>> --
>>>> Karl Denninger
>>>> karl@denninger.net <mailto:karl@denninger.net>
>>>> /The Market Ticker/
>>>> /[S/MIME encrypted email preferred]/
>>> %SPAMBLOCK-SYS: Matched [+Sean Chittenden <sean@chittenden.org>], message ok
>>>
>
> --
> Karl Denninger
> karl@denninger.net <mailto:karl@denninger.net>
> /The Market Ticker/
> /[S/MIME encrypted email preferred]/
--
Karl Denninger
karl@denninger.net <mailto:karl@denninger.net>
/The Market Ticker/
/[S/MIME encrypted email preferred]/
[-- Attachment #2 --]
0Ć *åHå„
ĀĆ0Ć10
`åHe�0Ć *åHå„
��Āé_0é[0éCĀ)0
*åHå„
�0üÉ1
0 UUS10UFlorida10U Niceville10U
Cuda Systems LLC1
0UCuda Systems LLC CA1"0 *åHå„
Cuda Systems LLC CA0
150421022159Z
200419022159Z0Z1
0 UUS10UFlorida10U
Cuda Systems LLC1
0
UKarl Denninger (OCSP)0é"0
*åHå„
�é�0é
é�╣äX°@vśkY▐
ÕT’Üq/vÕE“]└”5#éų»®MX“¢╚▄
Ā\8÷²L²J/V?õ5▓äÄDaÕ+
┐
┼sJųÕc╚*╗╠/õrč{╚╝ąn§¦Sł+�÷w"Ó)▀„┼─ģZ^£Dt®▓dCåOZŽŌ
~7ŁęQ ╠±'øĻ@Ų■¤a#išjłc█┤oZdB&¢«▀!Ćė£¼ōó-Ę< õ?
·ŁHÉŹāN„÷Å5½ä┤y
5¶}Fę|e
fŃéśÜ¦"VĄ
╩┘äiļąo²’7žó4÷ćńzną">öļ┌─a┴╝³é1q§Wu╔¢ŃbęF├’e└GEĆ&Ż3(│ŌK”h ¼∙┬ixŁG¹3óĀ╩!╠Ó#└e_XćŲ¼┐
µÓ±Ž£/,°ń$╝+·;╠4y╝┘
'žBõz<qTķ9║»Å┘_?rRU¬pnĮ5
ģāJn&R¤źx/ķp JÆyelŲ*╚pN┘8®/#╣9Ūu×£ļ°/Ż▀YP
¾īE¢ÅC)T§åõßY>ĒĄ~/╦śN[¼ēüõ Żv®╩yiš┴ŠDK╦ē
ä,╠^Ŗ"┤
?╔$¢ĮT8Æ╔▀Ž�vĢ&Ł┌Ø
±┴KĒ%zī8ōC @?ĶK{└9Īf`óé+¶«Ģ@,|ÄÆü▀
Möėbia�Żü¶0ü±07++0)0'+0åhttp://cudasystems.net:88880 U
0�0 `åHå°BĀ0
U
Ó0, `åHå°B
OpenSSL Generated Certificate0
U
┼
ö-ķ╔h\Fį¹§Żf ŅÕY0 U
#0Ć$qøØģ}³▌▌Į░╩ÆöĪ·ėm50
U
0ükarl@denninger.net0
*åHå„
�é�OwČb©┬ałb╔║x¦&ŅąUk±ŗ[Ļ£
„(OćjÜ©!ö╝³·%°pēŹ�MQ▓0I’!#ŖQ┬ķ”HõĀņ¤}.>~2āŗ█&D}Ģ<³wm_>╚V6║
vÅ
É]╦fÜ„>=¤N┘nļ+8;q Ówf╬░æć■Ę/Į»R”LyU·┤G#½bś}nŗ!D▌├ŌųųĆ
_ė╬upĢ|ōŹ_ŃŪ░×»c█Ś/¢%█źž°Ä
ÉnN8:▌dĘ█;Ī-▌UJß„d/ąm╔▄1~V▐éūÖ─ń■nN I╦Š$t¹F1&}Ł|?q? \─æĒXÜ°įæ■&\ä4VČ<lKōü╠ļÄŅ▌█«3%Am_Ėē▀ķ(▐šqÆŹ┤
Ø-(c▐ ū─AeµG²X)f}▄-╦ź6cÖžv~ĀĻK²gą8m~vŁ
ū;|█9Š:-iŖAŚæ³∙PÜ║ęøļ6ū█ÉnÖ-ä’Ļē.)Ų<[Ņ$KJėt“·½¶Śt/L4¹ß¢ŻŅ^CmĻu4všb{+ķČBŲGą$M╔╚ė0c§\ń°[M°Rö|┘0FįĖī▒ć█±©P&7┴ū§¤8®"4pĪÆōų±Ść„#▐
»«}ķįD
ZÉ9;V£9Ģ#>┤S¤w"ÓŪ[²UP7ö1é0é0ü¢0üÉ1
0 UUS10UFlorida10U Niceville10U
Cuda Systems LLC1
0UCuda Systems LLC CA1"0 *åHå„
Cuda Systems LLC CA)0
`åHe�ĀéM0 *åHå„
1
*åHå„
0
*åHå„
1
151015145621Z0O *åHå„
1B@x▄0x└æŲ╝pŽĆ▄y}E├łJBéå¼C)o¾ī±¼3¬ė”1▄aŲ<īćeO5|9£╠1Ędn║Ė ÷
*Y0l *åHå„
1_0]0
`åHe*0
`åHe0
*åHå„
0*åHå„
�Ć0
*åHå„
@0+0
*åHå„
(0ü¦ +é71üÖ0ü¢0üÉ1
0 UUS10UFlorida10U Niceville10U
Cuda Systems LLC1
0UCuda Systems LLC CA1"0 *åHå„
Cuda Systems LLC CA)0ü®
*åHå„
1üÖĀü¢0üÉ1
0 UUS10UFlorida10U Niceville10U
Cuda Systems LLC1
0UCuda Systems LLC CA1"0 *åHå„
Cuda Systems LLC CA)0
*åHå„
�é�xÓĶ@
▀ńb+[čDa▒█źķ┘'WU}¹|f┌08>▐
+čiOē▓øżO<xf.&┘³l┤÷śĢrFz
Ķ“╔ g¼█O╔6,üżäŖĘĄų±Ģ=�¾∙+ S^_méķé]K³ÖE╣ń£D
źpb]│5┘LåżŪ§{ß╣0äf£ńG▌
J│Kg×_<└╣į╗░╔ģōhš│Ģ╝å©į¹ØźTLį³S
:MĮ¤n„Ŗ„Ņ V<░ób}(|∙k▄ł¶■==gŖZi½ņ0?Į1┼ŗ├Ļ▓&NJu╩9░
’BŠ?é„>/ŗF═╣
»ŁPĮų╬FŽµ
4ĒnOc9īāÜ'Xēē ∙.
∙ļėēś;åłqŅ└į╠«’sž KQ¹ÓŅ¬┐Z\@�1
>i▐“żņ╬’Ķ{┐]w«Ć█å▓į∙ŗ *ž¬%Ē
ö║Ivg_æ“�SčÓi
öĘĆ║∙F╗pė<×õÆ\─
Ä76XÕKļ[õ“M&fl%>+∙Żė%¾LĆÕ▒Oa"ł\Ns#\DN?(¼~9ō{¤jęƵ ų┼Øā"šĘ
ŃY}c`ę²£m■S/▌Õ< k!oźŃ
CJ®#
aā¤t▓▒1ż,Ŗ╣ 1]²ÕW▓ ^G?q-§╝Ø<H¤+┘Z^pV”)������
{kind=link}
Want to link to this message? Use this URL: <https://mail-archive.FreeBSD.org/cgi/mid.cgi?561FBE95.6010107>