
Date: Thu, 27 Aug 2015 13:30:24 -0700 From: Sean Chittenden <sean@chittenden.org> To: Karl Denninger <karl@denninger.net> Cc: freebsd-fs@freebsd.org Subject: Re: Panic in ZFS during zfs recv (while snapshots being destroyed) Message-ID: <sig.0681f4fd27.ADD991B6-BCF2-4B11-A5D6-EF1DB585AA33@chittenden.org> In-Reply-To: <55DF7191.2080409@denninger.net> References: <55BB443E.8040801@denninger.net> <55CF7926.1030901@denninger.net> <55DF7191.2080409@denninger.net>
index | next in thread | previous in thread | raw e-mail
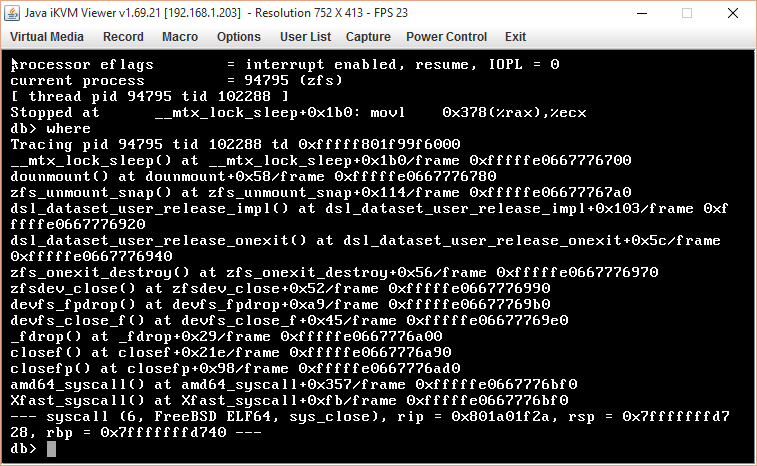
Have you tried disabling TRIM? We recently ran in to an issue where a `zfs delete` on a large dataset caused the host to panic because TRIM was tripping over the ZFS deadman timer. Disabling TRIM worked as valid workaround for us. ? You mentioned a recent move to SSDs, so this can happen, esp after the drive has experienced a little bit of actual work. ? -sc -- Sean Chittenden sean@chittenden.org > On Aug 27, 2015, at 13:22, Karl Denninger <karl@denninger.net> wrote: > > On 8/15/2015 12:38, Karl Denninger wrote: >> Update: >> >> This /appears /to be related to attempting to send or receive a >> /cloned /snapshot. >> >> I use /beadm /to manage boot environments and the crashes have all >> come while send/recv-ing the root pool, which is the one where these >> clones get created. It is /not /consistent within a given snapshot >> when it crashes and a second attempt (which does a "recovery" >> send/receive) succeeds every time -- I've yet to have it panic twice >> sequentially. >> >> I surmise that the problem comes about when a file in the cloned >> snapshot is modified, but this is a guess at this point. >> >> I'm going to try to force replication of the problem on my test system. >> >> On 7/31/2015 04:47, Karl Denninger wrote: >>> I have an automated script that runs zfs send/recv copies to bring a >>> backup data set into congruence with the running copies nightly. The >>> source has automated snapshots running on a fairly frequent basis >>> through zfs-auto-snapshot. >>> >>> Recently I have started having a panic show up about once a week during >>> the backup run, but it's inconsistent. It is in the same place, but I >>> cannot force it to repeat. >>> >>> The trap itself is a page fault in kernel mode in the zfs code at >>> zfs_unmount_snap(); here's the traceback from the kvm (sorry for the >>> image link but I don't have a better option right now.) >>> >>> I'll try to get a dump, this is a production machine with encrypted swap >>> so it's not normally turned on. >>> >>> Note that the pool that appears to be involved (the backup pool) has >>> passed a scrub and thus I would assume the on-disk structure is ok..... >>> but that might be an unfair assumption. It is always occurring in the >>> same dataset although there are a half-dozen that are sync'd -- if this >>> one (the first one) successfully completes during the run then all the >>> rest will as well (that is, whenever I restart the process it has always >>> failed here.) The source pool is also clean and passes a scrub. >>> >>> traceback is at http://www.denninger.net/kvmimage.png; apologies for the >>> image traceback but this is coming from a remote KVM. >>> >>> I first saw this on 10.1-STABLE and it is still happening on FreeBSD >>> 10.2-PRERELEASE #9 r285890M, which I updated to in an attempt to see if >>> the problem was something that had been addressed. >>> >>> >> >> -- >> Karl Denninger >> karl@denninger.net <mailto:karl@denninger.net> >> /The Market Ticker/ >> /[S/MIME encrypted email preferred]/ > > Second update: I have now taken another panic on 10.2-Stable, same deal, > but without any cloned snapshots in the source image. I had thought that > removing cloned snapshots might eliminate the issue; that is now out the > window. > > It ONLY happens on this one filesystem (the root one, incidentally) > which is fairly-recently created as I moved this machine from spinning > rust to SSDs for the OS and root pool -- and only when it is being > backed up by using zfs send | zfs recv (with the receive going to a > different pool in the same machine.) I have yet to be able to provoke > it when using zfs send to copy to a different machine on the same LAN, > but given that it is not able to be reproduced on demand I can't be > certain it's timing related (e.g. performance between the two pools in > question) or just that I haven't hit the unlucky combination. > > This looks like some sort of race condition and I will continue to see > if I can craft a case to make it occur "on demand" > > -- > Karl Denninger > karl@denninger.net <mailto:karl@denninger.net> > /The Market Ticker/ > /[S/MIME encrypted email preferred]/home | help
{kind=link}
Want to link to this message? Use this
URL: <https://mail-archive.FreeBSD.org/cgi/mid.cgi?sig.0681f4fd27.ADD991B6-BCF2-4B11-A5D6-EF1DB585AA33>