
Date: Thu, 27 Sep 2012 11:00:55 -0700 From: Rudy <crapsh@monkeybrains.net> To: freebsd-net@freebsd.org Subject: Re: ping: sendto: No buffer space available Message-ID: <50649457.4050701@monkeybrains.net> In-Reply-To: <50616D5C.705@gmail.com> References: <5060884C.3050709@monkeybrains.net> <506154C7.3040209@sepehrs.com> <50615F6F.1070105@monkeybrains.net> <50616D5C.705@gmail.com>
index | next in thread | previous in thread | raw e-mail
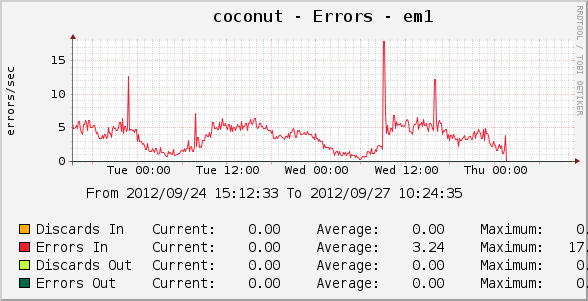
On 09/25/2012 01:37 AM, Hooman Fazaeli wrote: >> dev.em.1.link_irq: 6379725883 >> dev.em.2.link_irq: 6379294926 > Based on the strangely high value of dev.em.1.link_irq (which means too > many link > status changes: down -> up -> down -> ....), I guess the problem is the > same as > discussed in these threads: > > http://lists.freebsd.org/pipermail/freebsd-net/2011-November/030424.html > http://lists.freebsd.org/pipermail/freebsd-net/2012-March/031648.html > > To confirm, you may run this test: > > 1. Start a ping flood: ping -f <other-machine-ip> > 2. Let it run for a few seconds. > 3. Disconnect the cable. > 4. After a while, you should see "no buffer space" error. > 5. Stop ping flood. > 6. Re-connect the cable and wait 10 seconds. > 7. Start a normal ping. Error messages should show up again. > > To fix, upgrade to the latest e1000 driver from HEAD. > > The very high link_irq may be due to a loose connection. > Replace the patch cord and see if it helps. Thanks for the tips. I will test next time I am at the data center. For now, I rebooted after doubled the default nmbclusters and quadrupled the hw.em.rxd values in loader.conf. # loader.conf kern.ipc.nmbclusters=524288 hw.igb.rxd=4096 hw.igb.txd=4096 hw.em.rxd=4096 hw.em.txd=4096 Rebooting and/or the settings change seems to have stopped the errors. Here is a pretty little graph showing error rate on em1 for the past 3 days. http://www.monkeybrains.net/images/ErrorRate-em1.png Rudyhome | help
{kind=link}
Want to link to this message? Use this
URL: <https://mail-archive.FreeBSD.org/cgi/mid.cgi?50649457.4050701>